



В последнее время мы достаточно много общаемся с пользователями, которые самостоятельно делают отчеты в Power BI, используя данные из нашего сервиса myBI Connect. Большая часть их вопросов связана с созданием моделей данных и вычислением каких-либо специфических показателей при помощи DAX. Про последний можно найти достаточно большое количество справочников, разборов и статей, а вот материалов по моделированию значительно меньше. Поэтому мы решили написать ряд статей, которые помогут начинающим пользователям Power BI ознакомиться с основными принципами работы с ним. Это первая статья и в ней мы рассмотрим наиболее распространенный подход к созданию моделей данных.
Для начала, что вообще такое модели данных?
Большая часть пользователей Power BI начинает свой путь с создания визуализаций для плоских Excel табличек, которые уже обладают всей нужной информацией. Но рано или поздно этого перестает хватать, появляется желание загрузить больше таблиц, которые в идеале должны взаимодействовать друг с другом. Вот тут и начинается моделирование данных.
Данные в Power BI хранятся в виде отдельных таблиц между которыми можно создавать связи. Организованная структура этих таблиц и связей между ними и называется моделью данных. Модель является основой отчета, поэтому к ее разработке необходимо подходить максимально ответственно, неправильная организация данных может сильно усложнить вычисления DAX, или даже привести к некорректному отображению данных, что далее будет сложно отследить на этапе визуализации.
Прежде чем вы приступите к созданию отчета, вы должны четко определиться с целью, которая перед ним стоит, какую задачу он должен решить, и, конечно, с данными, которые вам для этого понадобятся. На основе этого вы сможете создать необходимую модель и только после этого приступить к работе над самим отчетом.
Именно для того чтобы избежать ошибок на начальном уровне создания отчетов мы и предлагаем вам ознакомиться с наиболее распространенным методом создания моделей. Конечно, это не единственный верный подход, которому нужно следовать всегда и везде, но он является логически целостным и довольно легко масштабируемым, что позволяет создавать как простые, так и сложные модели, в которых вам будет легко ориентироваться в дальнейшем.
Схема Звезда
На сегодняшний день большинство экспертов в один голос утверждают, что наиболее оптимальная модель в Power BI это Звезда. Мы в свою очередь исключением не являемся и сами используем данный принцип. Так что же такое «звезда» и чем она так хороша?
Схема Звезда — это способ организации данных, основанный на логическом разделении их на два типа, для хранения которых используются таблицы измерений и таблицы фактов. Таблицы измерений содержат набор описательных атрибутов, характеризующих объект. Это могут такие сведения как категория объекта, его название, какие-то физические характеристики объекта и т.д. Таблицы фактов содержат сведения о событиях, в которые вовлечены те или иные объекты. На практике это выглядит как связи с таблицами измерений в виде внешних ключей и цифровые показатели, характеризующие событие, такие как цена, количество и т.д.
В качестве примера мы будем рассматривать модель, созданную на основе выгрузки данных по рекламе из сервиса Яндекс.Директ:
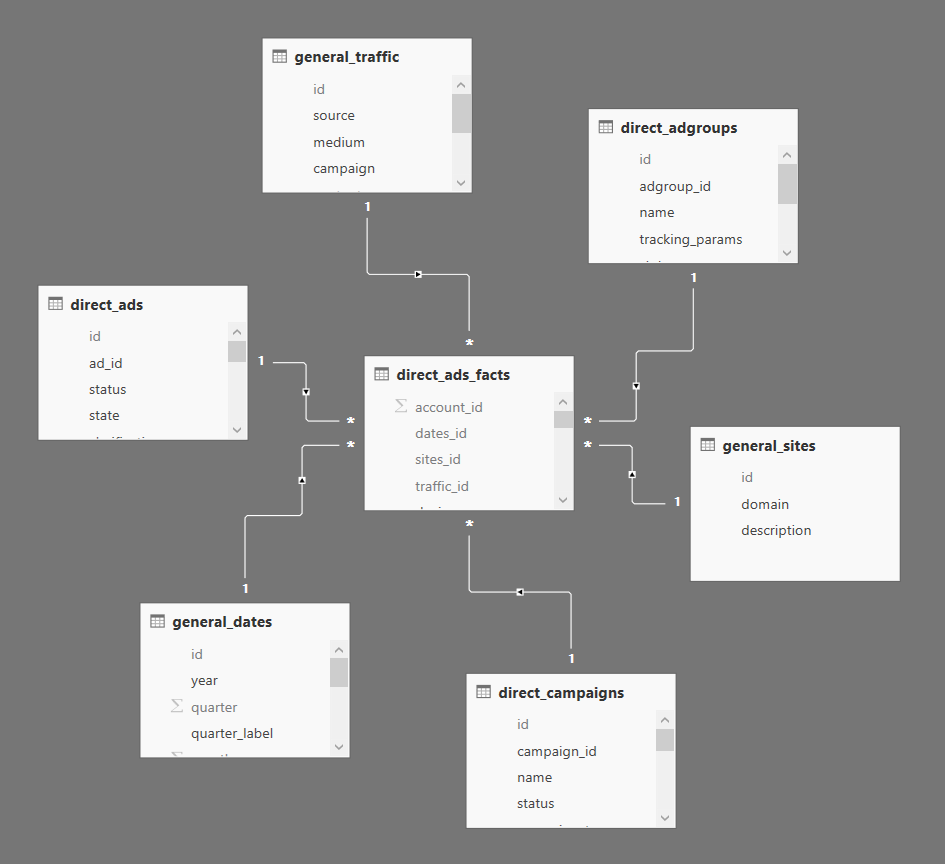
На скриншоте представлена классическая Звезда, в центре которой находится таблица фактов, вокруг которой размещены таблицы измерений. Если говорить именно о нашем примере, то в таблицах измерений содержатся следующие сведения:
- параметры кампаний;
- параметры групп объявлений;
- параметры объявлений;
- домены;
- UTM-метки;
- даты.
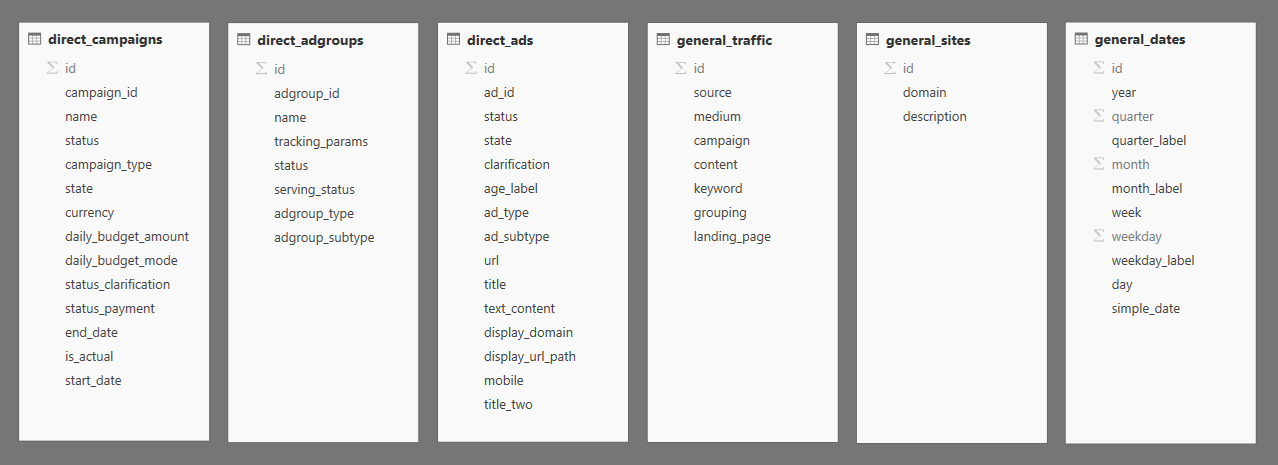
В таблице фактов содержатся ссылки на таблицы измерений и статистика по объявлениям:
- показы на поиске и в рекламной сети;
- клики на поиске и в рекламной сети;
- расходы на поиске и в рекламной сети;
- средняя позиция показа;
- средняя позиция клика.
Основной принцип, который нельзя нарушать: таблицы измерений не могут иметь связи между собой. Это необходимо соблюдать всегда. К примеру вы решите связать таблицы содержащие сведения о кампаниях и группах объявлений — это кажется вполне логичным, но это может вызвать неоднозначность в связях (что запрещено в Power BI) или просто ограничить вас в использовании данных, находящихся в одной из этих таблиц. Все связи между разными объектами реализуются только через таблицы фактов.
Однако ради справедливости стоит отметить, что это правило не всегда является абсолютным.
Схема Снежинка
Все-таки связи между таблицами измерений возможны, и, хотя это является частным случаем Звезды, подобный способ организации данных носит название Снежинка. Пример подобной структуры показан на следующем скриншоте, на котором появились новые таблицы по таргетингу на регионы, связанному с группами объявлений, и быстрым ссылкам, связанным с объявлениями:
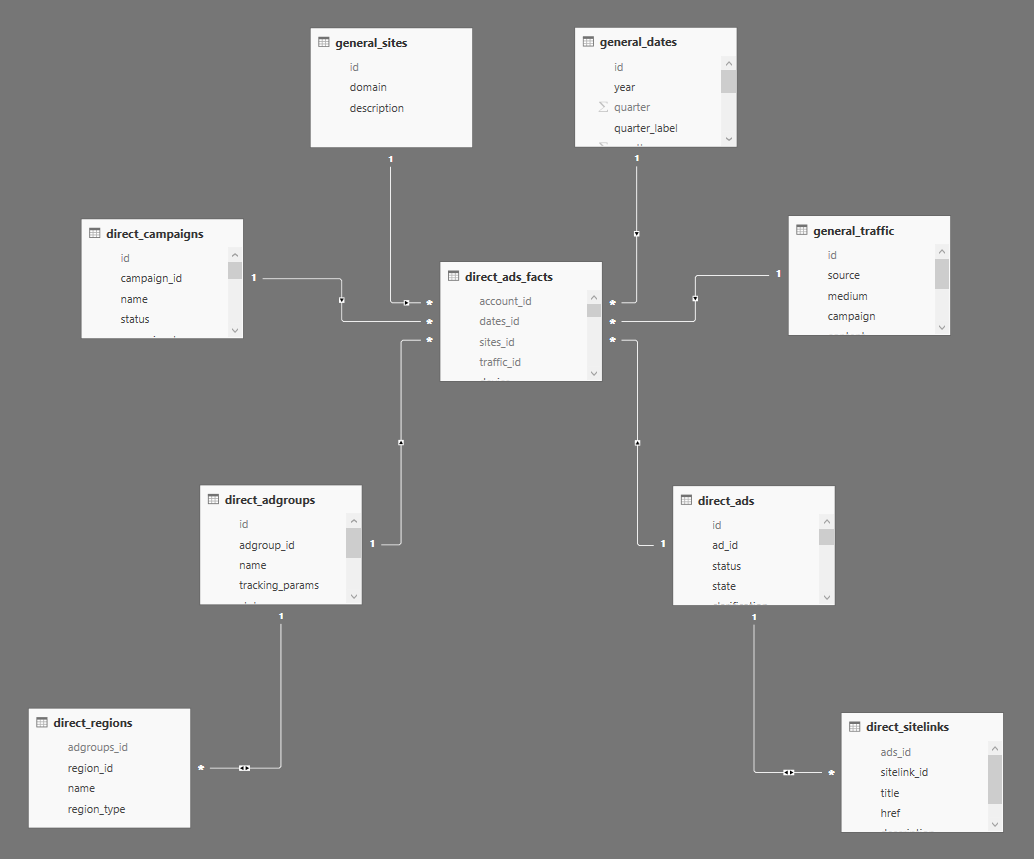
Подобный способ так же имеет право быть, но его следует использовать с большей осторожностью, а лучше вообще пытаться избегать по мере возможности. Основная причина в том, что чем больше связей мы имеем, тем больше шансов в них запутаться. Кроме этого наличие большого количества иерархических связей ( A -> B -> C -> D … ) может негативно сказаться на производительности.
В приведенном примере мы просто не можем сделать иначе, поэтому и применяем подобный подход: у одного объявления может быть несколько быстрых ссылок и одна группа объявлений может быть нацелена на показ в нескольких регионах. В тоже время мы имеем только иерархические связи, а не циклические, что позволяет избежать неоднозначности о которой упоминалось выше.
Как использовать модель?
Надеюсь, что основной принцип, заложенный в схемах Звезда и Снежинка стал понятен, поэтому сейчас мы можем перейти к рассмотрению того как подобная модель используется в Power BI.
На самом деле в данном случае все довольно просто, необходимо лишь следовать одному правилу: таблицы измерений используются для формирования срезов, а все меры вычисляются на основе таблиц фактов.
Для примера рассмотрим простую меру, которая вычисляет количество показов всех объявлений, принадлежащих кампаниям с типом «Текстово-графические объявления»:
Количество показов = CALCULATE ( SUM ( 'direct_ads_facts'[impressions] ); FILTER ( 'direct_campaigns'; 'direct_campaigns'[campaign_type] = "TEXT_CAMPAIGN" ) )
По данной мере видно, что мы накладываем фильтр на таблицу, содержащую сведения по кампаниям direct_campaigns, а количество показов считаем по таблице фактов direct_ads_facts. Благодаря существующей связи между этими таблицами фильтр наложенный на таблицу измерений распространяется и на таблицу фактов, что и позволяет вычислить необходимое нам значение:
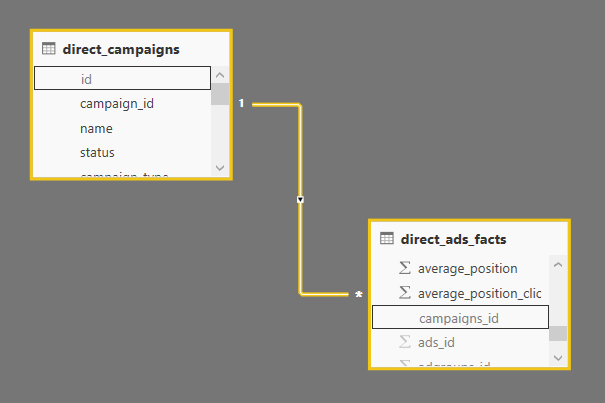
В данном случае мы используем однонаправленную связь «один ко многим» от таблицы измерений к таблице фактов. Это означает, что одна запись из таблицы direct_campaigns может быть связана с несколькими записями в таблице direct_ads_facts, а фильтр распространяется только от таблицы измерений к таблице фактов, но не наоборот. Данная ситуация является наиболее типичной и используется в 80% случаев, использовать иную кратность или направление кросс-фильтрации необходимо с большой осторожностью.
Какие преимущества имеют эти схемы?
Данный подход на протяжении многих лет использовался для проектирования аналитических баз данных и отличается от других именно своей простотой получения необходимых сведений. В тоже время — это только вершина айсберга, самое интересное как раз вытекает из основного принципа разделения данных на логические элементы (объекты). Дело в том, что при использовании различных источников данных, некоторые объекты могут повторяться, но здесь стоит отметить что речь идет не столько о их названиях, сколько о их структуре. К примеру, если мы возьмем рекламные кампании в том же Яндекс.Директ и Facebook, то по своему существу они похожи, но по структуре данных отличаются. В тоже время если мы возьмем UTM-метки, которыми размечены URL объявлений в этих кампаниях, или дату, за которую мы выгрузили статистику, то они одинаковы во всех смыслах. Поэтому такие данные можно вынести отдельно в так называемые общие таблицы измерений, которые одинаковы и могут использоваться в разных таблицах фактов:
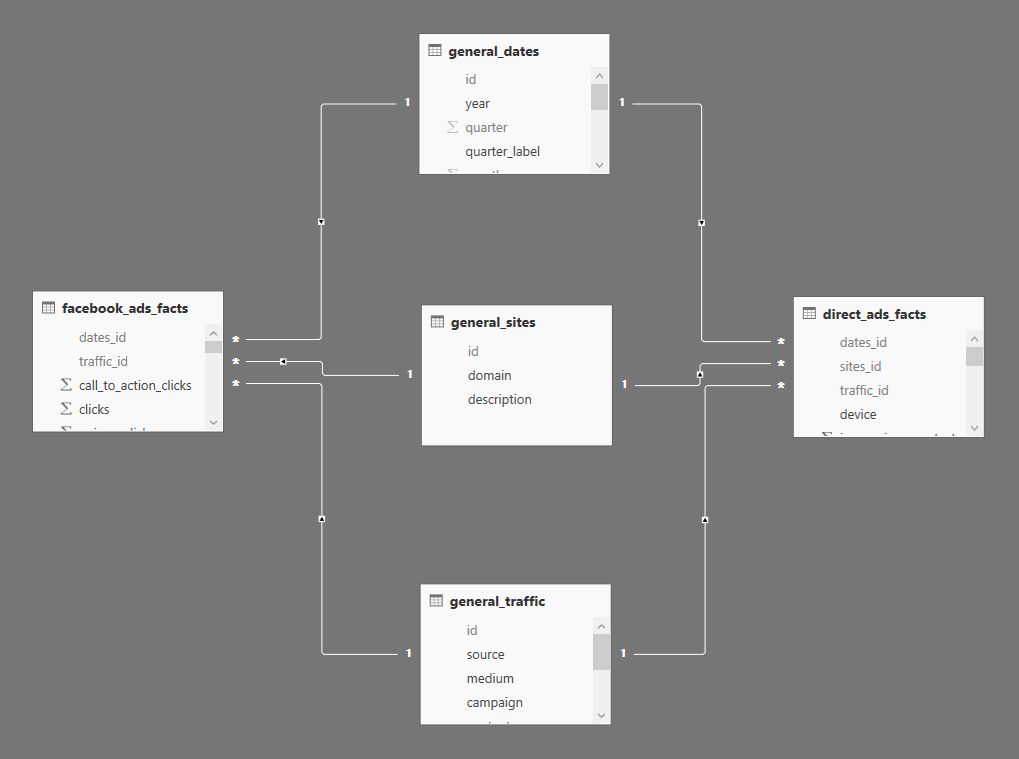
В данном случае мы имеем две таблицы фактов, которые находятся по бокам, и три таблицы общих измерений, которые размещены по середине. Данные были выгружены их разных рекламных площадок, но учитывая их организацию, мы можем их использовать совместно, т.е. посчитать общий расход на рекламу по дням или сайтам. Более того в эту модель можно легко добавить данные из других рекламных площадок или Google Analytics.
Обратная сторона модели
Сложно сказать, что у данного подхода есть явные недостатки, но ради справедливости следует отметит тот факт, что при его использовании есть вероятность незначительного увеличения объема памяти, занимаемого моделью, и как следствие некоторое снижение производительности, по сравнению с тем, если бы все данные хранились в одной большой таблице. В тоже время не стоит забывать, что на практике мы редко имеем возможность работы с такого рода данными… Поэтому возможность получения прозрачности данных и масштабируемости модели, за счет незначительного снижения производительности сложно назвать недостатком.
Мы прекрасно понимаем, что в рамках одной статьи невозможно описать все тонкости моделирования, но в то же время мы и не ставили перед собой такой задачи, а хотели лишь выделить основные моменты, которые возможно заставят читателей задуматься о роли создания моделей и постараться разобраться в этой интересной теме чуть-чуть более подробно. Со своей стороны, мы не планируем останавливаться на этом и в следующий раз постараемся рассмотреть более практичный и немного более сложный пример, чем те, которые мы рассматривали в этой статье.
Если у Вас остались вопросы или комментарии, пожалуйста, напишите их под этой статьей. И спасибо, что дочитали, надеемся это было полезным)
UPD. Мы продолжили развивать тему моделирования данных и опубликовали следующую статью, в которой рассматриваем пример построения модели на данных Google Analytics.





















