


Привет, меня зовут Антон Фирсов.
С 2015 года я руковожу ИТ подразделениями, работаю с бизнес-заказчиками, управляю разработкой внутренних продуктов и отчетностью.
В 2020-ом полностью посвятил себя Power BI и занимаюсь частной практикой.
Эту статью я написал специально для Power BI Russia, в ней хочу рассказать об одном из своих последних проектов, а также поделиться некоторыми мыслями, наблюдениями и техническими аспектами. Надеюсь, материал будет интересен и полезен как BI-разработчику, независимо от уровня зрелости, так и уполномоченным лицам со стороны бизнеса.
Ну что, поехали.
“Все совпадения случайны”
“Мнение автора может не совпадать с его точкой зрения” ©
Все мы помним верёвочный барометр.  Тем, кто не помнит, я напомню: на столбе висит верёвка, рядом с ней инструкция, как по верёвке однозначно определить погоду:
Тем, кто не помнит, я напомню: на столбе висит верёвка, рядом с ней инструкция, как по верёвке однозначно определить погоду:
Верёвка мокрая — идёт дождь;
Верёвка отбрасывает тень — ясно;
Верёвку не видно — сильный туман;
И так далее…
Задача хорошего аналитика, на мой взгляд, конструировать такие “барометры”)
Как пишет Талеб в “Антихрупкости”: “Очевидные решения (неуязвимые в отношении ошибок) требуют не более одной причины. Никто не говорит: “Он уголовник, убивший много людей, а еще он отвратительно ведёт себя за столом, у него пахнет изо рта и он скверно водит машину”.
Переводя на язык аналитики: если вы хотите, чтобы ваш отчет был функционален и помогал в принятии решений, он должен содержать одну-две ключевых метрики и фокусировать пользователя на них, иначе вы его (пользователя) только запутаете. Поиск этих метрик и есть наша основная задача. Это первое.
Вторая важная вещь — визуализация.
Я склонен считать, что не играет роли, на каком уровне вы представляете информацию: совету директоров корпорации, руководителю направления или менеджеру магазина розничной торговли плюшевыми бегемотами. Во всех случаях ваш идеальный отчет — тот, что не перестанет работать, даже если убрать с него все цифры. Я нередко вижу решения, где парочке скромных графиков соседствует таблица на два десятка столбцов с рядами чисел мелким шрифтом.
Что-нибудь вроде этого:
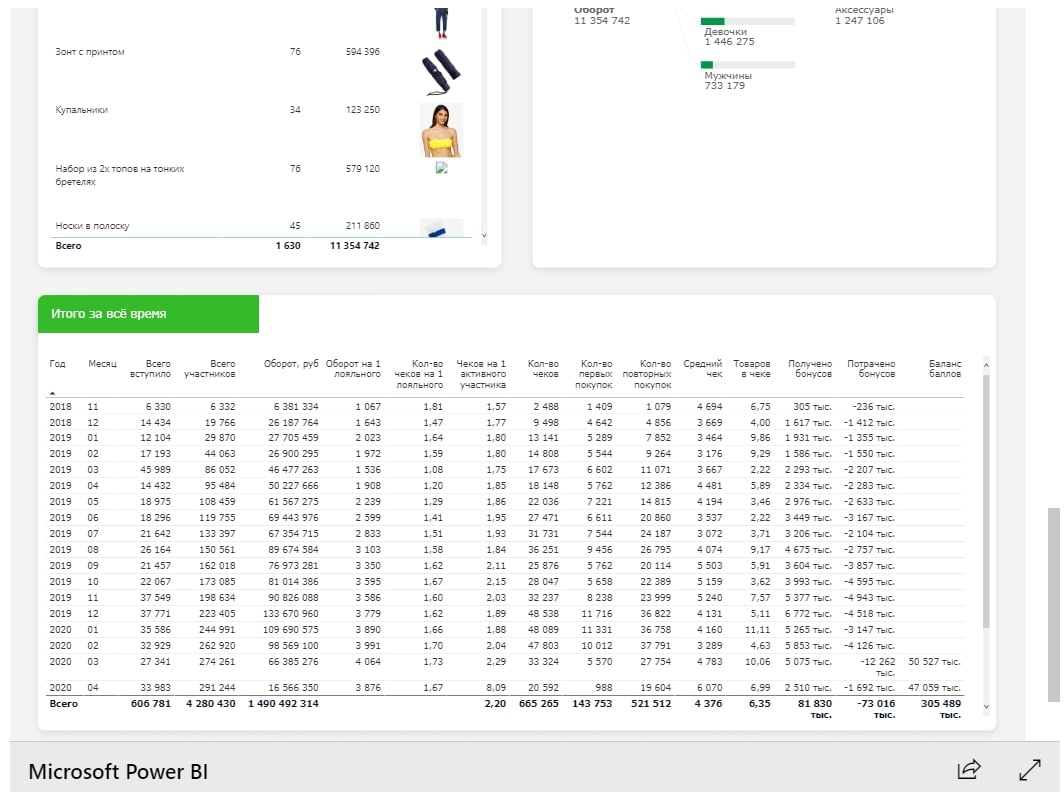
Картинка из из этого кейса нашего блога (примечание редактора).
Другая крайность:
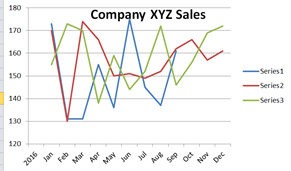
А бывает, что и всё вместе:
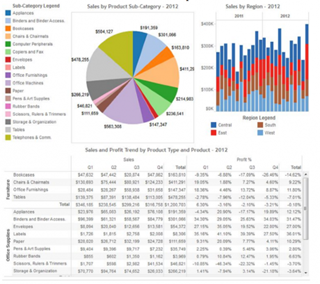
Пользуясь случаем, хочу передать привет тем, кто это создаёт. Спасибо, друзья, пока вы есть — я не останусь без работы.
Итак, вот два простых правила:
1. Находим ключевое;
2. Делаем его наглядным.
Давайте посмотрим, как их можно применить.
Перед вами дашборд:
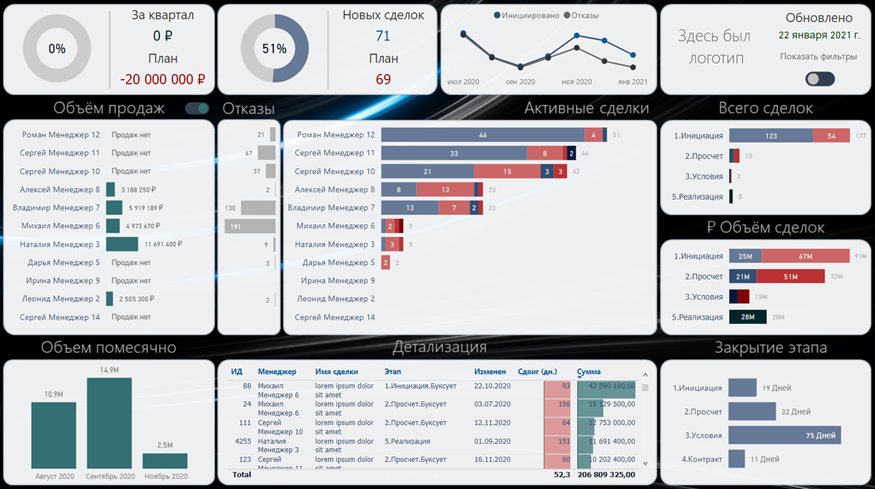
(чуть дальше в него можно будет поклацать мышкой).
Самый активный элемент — центральный, отражает ключевой показатель отдела продаж: количество активных сделок в разрезе менеджера.
Как из него делать выводы? Очень просто:

Сделки (лиды, если вам так больше нравится) разбиты на этапы. Каждый этап имеет срок.
Синий — успеваем.
Красный — буксуем или зависли.
Чем темнее оттенок, тем ближе сделка к заключению контракта.
Сводка, повторюсь, очень простая:
Больше синего — люди работают.
Больше красного — что-то не так.
Пустое поле — быть беде.
Верёвка мокрая — идёт дождь.
Надеюсь, идея понятна.
Ради эксперимента уберем цифры:

Видим, что элемент не только не потерял, но даже приобрёл в читаемости. Избавившись от нарратива в виде чисел, мы освободили разум для восприятия информации через образ, в данном случае пропорцию цвета.
Задайте себе вопрос: сколько секунд заняла оценка ситуации?
“Магия” — скажете вы.
“Мы так устроены” — отвечу я.
Вам не нужны рулетка и штангенциркуль, чтобы сказать, что ваша женщина самая красивая. Вы не будете изучать характеристики автомобиля, если вам не нравится, как он выглядит.
Эта статья была бы на 59,37% скучнее, если бы я не сопровождал ее иллюстрациями. Шутка — она была бы скучной, как большинство отчётов.
Механизм, по которому мы принимаем решения (в том числе в бизнесе), называется эвристикой, и он не требует слишком точной оценки. Наш разум все равно преобразует цифры в более естественные “человеческие” величины: 87% это “почти целое”, а 459 из 1000 — “чуть меньше половины”. Если вы не станете грузить пользователя лишними деталями, а, повторюсь, сделаете ключевое наглядным — ценность вашей работы резко возрастет.
Давайте вернемся к задаче и посмотрим, как мы решали, что выводить на дашборд.

Ко мне обратился собственник компании, которая занимается AR-аттракционами для детей и интерактивными выставками.
Запрос, в общих чертах, звучал так: “Я не понимаю, что происходит с продажами, вижу только вход и выход. Всё, что в середине — черная коробка. Хочу видеть, кто и как работает в промежутке”.
В компании недавно сменился РОП и всю дальнейшую работу мы проводили с ним.
Сразу оговорюсь, что задача введения авторитарных KPI в компании не стояла, отношение достаточно либеральное, но не к тунеядству. За сквозную аналитику отвечает Roistat, поэтому маркетинга на дашборде также нет, с ним будем разбираться в следующих эпизодах.
Для начала пришлось изучить продукт и бизнес-процесс.
Что имеем на входе:
- Коробочные и индивидуальные решения;
- Затяжной процесс поставки: от 3 мес до года, а иногда и больше (с последним, впрочем, мы и хотели побороться);
- Несколько воронок в CRM с разными шагами для разных продуктов;
- Объем отдельных сделок отличается в 10-20 раз;
- Нишевый B2B продукт: малое количество лидов и совсем крошечное — успешных сделок;
Включаем логику и здравый смысл:
При выборке в 30-50 успешных сделок в год на компанию, вклад менеджера или скрипта в объем и конверсию оценить невозможно. Вы никогда наверняка не скажете, что именно сработает в следующий раз. Можете со мной спорить и предлагать гипотезы, но, на мой взгляд, здесь куда большую роль играет фактор удачи (случайности), чем некая закономерность событий или действий. Думаем: а что тогда однозначно ведет нас к результату? Как подчинить себе эту случайность? Очевидно, только увеличив количество самих сделок и скорость работы с ними. И только через эти показатели и возможно объективно оценить работу продавца и отдела. Иными словами, это и есть наши ключевые метрики. Звонки и встречи вложены в сами сделки. Причины отказа — ну хорошо, их две: “Дорого” и “Клиент пропал”, что тут анализировать?
В итоге на доске остались:
- Динамика новых сделок;
- Количество активных сделок и их состояние;
- Скорость прохождения сделки через этап;
- План/факт продаж;
- Объем ₽ по активным сделкам для прогноза выручки;
- Количество отказов как косвенный показатель проделанной работы и для анализа выбросов;
Снова повторю: ищите ключевое. То, что точно влияет на результат и что нельзя трактовать двояко. Не бегите выводить в отчет все цифры, которые смогли откопать. Если ваш заказчик продает пояса для похудения и у него в месяц несколько сотен лидов на менеджера, то конверсия имеет фундаментальный смысл — она позволит оценить, как отдельный сотрудник обрабатывает типовые заявки, найти лучшего и скопировать у него алгоритм. Если же продукт сложный, а продавцов больше, чем успешных сделок в месяц — конверсия бесполезна, только мутит воду.
Вспоминаем: верёвку не видно — сильный туман.
Если кому-то кажется, что я говорю очевидные вещи — парни, большое спасибо, последние несколько абзацев были не для вас. Простите за потраченное время. Тем не менее, многие наши коллеги этого не понимают и искренне думают, что в голове у заказчика сидит мысль, вроде: “Я заплатил за все данные — я хочу видеть все данные”. Это не так. Друзья, таким подходом вы лишь создаете плохой имидж нашей работе и отпугиваете от BI потенциальных клиентов. Этой статьей я пытаюсь немного изменить тренд.
Пилот учится 5 лет. Не делайте из заказчика пилота.

Снова немного ушли в сторону.
Давайте вернемся к доске и рассмотрим ее визуальные элементы, а в конце я покажу пару интересных примеров DAX-кода.
Основная диаграмма, как я уже говорил, отражает активные на текущий момент сделки:

На входе у нас была AmoCRM с разными воронками для каждого продукта, которые включали по 10-15 шагов. Я предложил свести все воронки к нескольким простым этапам для наглядности. Далее мы с РОПом установили сроки этим этапам по каждой из воронок.
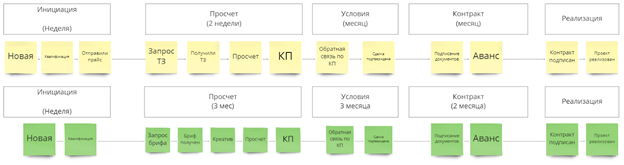
Одна из фишек доски в том, что она “помнит” дату входа в этап:

Если вы просрочили “Просчет”, то даже если в CRM вы кинете сделку в “Условия”, а потом вернете обратно — диаграмма все равно подсветит ее красным. Это заставляет менеджеров увеличивать скорость работы, либо закрывать/архивировать лид, потому что за красный можно получить по голове. Если менеджер закрыл все лиды и сидит с пустой доской — по голове тоже обязательно прилетит. Хочешь — не хочешь, а шевелиться придётся.

Сроки, как и логику этапов, можно настраивать через Google Sheets:
Отдельно подчеркну, что работа менеджеров в CRM при этом не изменилась.
Идем дальше.
Здесь, я думаю, пояснения не нужны. Коротко и лаконично о главном:

Вот эта штука интереснее:

Здесь динамика новых сделок и отказы по ним.
Синий график отслеживает, сколько сделок было взято в конкретном месяце.
Серый — ищет отказы по этим же сделкам на всем временном отрезке, игнорируя контекст дат.
Если сделка была инициирована в ноябре, а отказ по ней случился в январе, то график отказов все равно отразит это в ноябре.
Что мы показали:
- Как меняется число новых сделок от месяца к месяцу;
- Сколько старых “новых” уже ушло в отказ;
- Активные на текущий момент — область между двумя графиками, максимально наглядно;
А еще можно увидеть, что конверсия исторически низкая и нет смысла эти полпроцента несчастные где-то еще на доске отражать.
Чего мы избежали: неоднозначной ситуации, когда число отказов превысило число новых сделок. Так бывает, если смотреть на новые и на отказы независимо друг от друга. Здесь же серый всегда будет стремиться к синему, но никогда не залезет выше.
Представьте, что в декабре продажники закрыли все старые лиды и у вас 120% отказов, но при этом есть выручка. Куда вы отправите того аналитика?
Также элемент удобно использовать в качестве фильтра дат, не открывая основную панель фильтров.
Через переключатель можно увидеть объем денег:
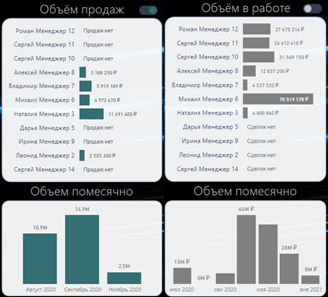
Серый — по сделкам в работе;
Оливковый — по контрактам.
Первое позволяет прикинуть прогноз будущих продаж, второе — оценить эффективность работы менеджеров по самому главному показателю — выручке.
Панель в поддержку основной диаграмме:

Количество сделок и объем ₽ на каждом из этапов. Реализации не отражены на основной диаграмме, так как выходят за рамки бизнес-процесса продавца, он с ними уже не работает. Но для справки они присутствуют здесь. С помощью этой панели также удобно фильтровать элементы и углубляться в ситуацию.
Цветовой код тот же: красная часть диаграммы — просроченные сделки.
Срок закрытия этапа:

Отражает среднее значение разницы между входом и выходом из этапа.
Если кратко — спидометр. Можно увидеть, на каком этапе ваши сделки в среднем “висят” дольше всего. В демо скрыт фильтр по воронкам, в “боевом” дашборде он присутствует.
Подробные сведения о сделках:

Просто небольшая табличка в помощь РОПу. Позволяет работать с отдельными сделками, сортировать их по разным полям, изучать зависания и перспективы продаж.
Для большей наглядности сдвиг по срокам и сумма представлены отдельными диаграммами.
По элементам вроде всё.
Еще пару слов про цвета:

Немного сумбурно, но, я думаю, видно, как работает цветовое кодирование на всей доске:
Синий — что-то про сделки
Оливковый — про деньги
Серый — что-то уже или еще неактивное
Красный — обрати внимание
Это делает дашборд более интуитивным, дает глазу отдыхать и повышает читаемость.
Ну а теперь можете сами потыкать в разные элементы и сделать для себя выводы:
Давайте короткий итог подведем.
Итак, мы получили инструмент, который:
а) Сообщает нам “погоду” в отделе продаж;
б) Нежно пинает наших менеджеров, чтобы они быстрее работали со сделками;
в) Говорит, на каких этапах мы чаще и сильнее всего застреваем;
г) Отражает динамику новых сделок;
д) Находит зависшие сделки;
е) Позволяет прикинуть, что мы можем заработать в будущем;
Дальше список можете продолжить сами.
Пока я писал эту статью, у меня родился “оптимизированный” вариант дашборда для собственника:
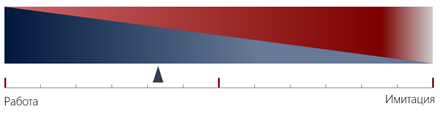
Очень просто: ближе к левой части результат будет хороший, ближе к правой — плохой.
Давайте напоследок заглянем “под капот” парочке элементов и на этом закончим.
Если вы не BI-разработчик, информация ниже не несёт вам никакой пользы, можете не тратить время.
Сам дашборд собран на данных AmoCRM с помощью myBI Connect. Структура таблиц сервиса известна и достаточно удобна, кстати, размещена тут.
Посмотрим сначала вот на этот элемент:

Напомню, что шаги из CRM у нас сводятся к этапам верхнего уровня, которые живут в Google-таблицах:
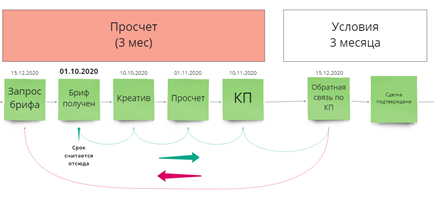
Чтобы понять, сколько времени занял этап, надо найти дату входа и дату выхода из него.
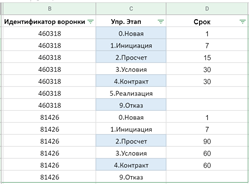
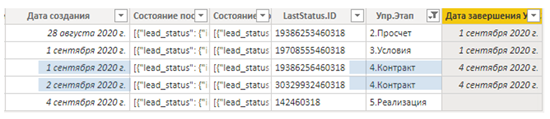
Вот кусок таблицы “АМО События сделок”:

На картинке виден исходный столбец “Дата создания” и вычисляемый столбец “Дата завершения”.
Сделка вышла на “Просчет” 28 августа, а 1 сентября перешла в следующий этап: “Условия”.
Из “Условий” сделка вышла в тот же день — 1 сентября, и перешла в “Контракт”.
“Контракт”, несмотря на то, что внутри этапа были какие-то движения по внутренним статусам в CRM, окончательно закрылся только 4 сентября, перейдя к “Реализации”.
- Просчет > Условия (1 сентября)
- Условия > Контракт (1 сентября)
- Контракт > Реализация (4 сентября)
Таким образом, вычисляемый столбец говорит нам, когда наш этап окончательно закрылся. Этап получен через банальный RELATED по связи через LastStatus.ID.
Давайте теперь посмотрим код столбца:
Дата завершения Упр.Этапа = VAR CurrentID__ = 'AMO События сделок'[Идентификатор сделки] VAR CurrrentStage__ = 'AMO События сделок'[Упр.Этап] VAR StartDate = 'AMO События сделок'[Дата создания] RETURN CALCULATE( min( 'AMO События сделок'[Дата создания] ), FILTER( 'AMO События сделок', CurrentID__ = 'AMO События сделок'[Идентификатор сделки] && CurrrentStage__ < 'AMO События сделок'[Упр.Этап] && StartDate <= 'AMO События сделок'[Дата создания] ) )
Что здесь происходит?
Поскольку мы вычисляем столбец, у нас уже существует контекст строки.
Зададим переменные, взяв из контекста то, что нам нужно:
CurrentID — идентификатор сделки
CurrentStage — текущий Этап
StartDate — дата входа в Этап
Для каждой строки в переменной будет лежать свое значение.
Переходим к вычислениям:
FILTER является функцией-итератором, которая перебирает таблицу по условию и возвращает таблицу-результат,
CALCULATE нужен для того, чтобы использовать FILTER перед MIN.
Что код делает дальше:
1) Внутри FILTER вычисляется табличное выражение:
- Возьми исходную таблицу целиком
- Верни строки, где:
- ИД Сделки такой же, как в переменной
- Этап следующий за этапом в переменной
- Дата создания больше или равна дате в переменной
2) Результат табличного выражения из шага 1 поступает на вход функции MIN, которая и возвращает минимальное значение даты в столбец.
Чутьё подсказывает, что выражение можно было бы переписать иначе:
MINX(FILTER(‘таблица’, условие), [Столбец с датой])
Но для движка разницы скорее всего не будет, а с CALCULATE нагляднее.
Еще живы? Продолжаем 🙂
У нас получилась дата закрытия этапа. Теперь нам надо посчитать разницу в днях между входом и выходом и вывести среднее значение. Казалось бы:
AVERAGEX('таблица',DATEDIFF(дата1,дата2)).
Однако, всё не так просто. Мы же видим на картинке, что этапы верхнего уровня повторяются, так как сделка пляшет по шагам внутри самой CRM. То есть “Контракт” у нас посчитается дважды со значениями 2 и 3 и испортит наше среднее. Так делать нельзя.
Как поступить? Нужно сводить данные.
Вот вам второй кусок кода:
СрокЭтапа = VAR SumTable__ = CALCULATETABLE ( SUMMARIZE ( 'AMO События сделок', 'AMO События сделок'[Идентификатор сделки], 'AMO События сделок'[Упр.Этап], "Дата Входа",min('AMO События сделок'[Дата создания].[Date]), "Дата Выхода",MAX('AMO События сделок'[Дата завершения Упр.Этапа].[Date]) ), ALL('Calendar'), FILTER('Calendar','Calendar'[Date] <= MAX('Calendar'[Date])) ) RETURN CALCULATE ( AVERAGEX ( SumTable__, DATEDIFF([Дата Входа],[Дата Выхода],DAY) ), FILTER ( SumTable__, NOT(ISBLANK([Дата Выхода])) ) )
Что мы делаем здесь:
Сначала формируем итоговую таблицу с помощью Summarize:
| Ид сделки | Этап | Самая ранняя дата входа в Этап | Финальная дата выхода из Этапа |
Сведя таблицу по этапу и взяв только значения MIN и MAX для дат, мы избежим двойного подсчета разницы дат по этапу “Контракт” — в таблице он встретится только один раз.
MAX на самом деле можно и не брать, потому что, как мы видели по коду выше, значение выхода из Этапа у нас всегда одинаковое. Однако, на всякий случай, я все-таки использовал MAX, вдруг с данными произойдёт какая-то коллизия, которую я не мог предусмотреть.
Дальше всё просто. Считаем средний DATEDIFF по получившейся на шаге 1 таблице, убирая все этапы, где дата выхода нам неизвестна (пустая), то есть этап еще не закрыт.
Опытный даксер скорее всего заметил, что таблица у нас формируется не помесячно, а нарастающим итогом, о чем говорит конструкция
ALL('Calendar'), FILTER('Calendar','Calendar'[Date] <= MAX('Calendar'[Date]).
Действительно, при нашем цикле сделки нет смысла смотреть на эти данные помесячно, очень маленькая выборка. А вот на всей дистанции — работает.
Ну и по итогу диаграмма:
Комментарий: автор знает, что вычисляемых столбцов лучше избегать, а все вычисления можно было реализовать и в одной мере, используя, например, GENERATE или даже ADDCOLUMNS для создания сводной таблицы. Однако, это сильно ухудшило бы читаемость кода, представьте хотя бы работу с фильтрами. В данном проекте вычисляемый столбец большого влияния на производительность не оказал, поэтому “для потомков” я решил его оставить.
Вот на эту штуку тоже давайте взглянем:
Как я и говорил, серый график ищет только сделки, которые отразил синий, и привязывает их к тому же месяцу — где бы ни произошло событие.
С корабля на бал!
Denial.Relates.To.Init+ = VAR SumTable__ = CALCULATETABLE ( VALUES( 'AMO События сделок'[Идентификатор сделки] ), FILTER( 'AMO События сделок', 'AMO События сделок'[Упр.Этап] IN {"1.Инициация", "0.Новая"} ) ) RETURN COUNTX( SumTable__, CALCULATE ( COUNTROWS( FILTER( 'AMO События сделок', [Идентификатор сделки] = 'AMO События сделок'[Идентификатор сделки] && 'AMO События сделок'[Упр.Этап] = "9.Отказ" ) ), ALL('AMO События сделок'[Дата создания]), REMOVEFILTERS('$Summarized_Stages'[Упр.Этап.Буксует]) ) )
Что мы делаем:
1) Шаг один — кладём в переменную SumTable таблицу с единственным столбцом, которая будет содержать только уникальный ИД сделок, которые когда-либо прошли через этапы “Инициация” и “Новая” (в исторических данных есть те, кто сразу пришел в “Условия” или находился в неизвестном науке статусе).
2) Шаг два: запускаем итератор COUNTX:
- На вход итератора подаём таблицу, которую ранее собрали;
- Благодаря итератору мы создали контекст строки, который содержит единственное значение ИД сделки;
- Теперь запускаем COUNTROWS чтобы через него получить строки;
- Внутри COUNTROWS запускаем второй итератор — FILTER, создавая внутренний (вложенный) контекст строки;
- Теперь обращаемся из внутреннего контекста строки во внешний и смотрим только на строки, в которых совпадают значения ИД сделки обоих контекстов. Возвращаем строку в COUNTROWS только в случае, если у внутреннего контекста нашлась хотя бы одна строка, где Этап = Отказ;
- Перед тем, как фильтр начнет перебирать таблицу внутри COUNTROWS, мы заранее изменяем внешний контекст фильтра через CALCULATE, чтобы внутренний итератор работал на всем временном отрезке, а не только с видимой датой, с помощью ALL(‘Calendar’)
- REMOVEFILTERS в конце нужен, чтобы центральная диаграмма активных сделок не пыталась фильтровать наш график с помощью своих Этапов — они отличаются от исходных наличием дополнительного статуса “Буксует”.
Таким образом, мы просто использовали два итератора, один вложенный в другой. Пример очень похож на предыдущий, только там контекст строки был создан вычисляемым столбцом, а здесь нам пришлось создавать его с помощью COUNTX.
Готово, вы восхитительны.
А на на этом у меня всё.
Надеюсь, что статья окажется интересной и полезной читателю. Напишите в комментариях, что было наиболее ценным лично для вас, а я буду признателен и учту это в будущих публикациях. Конструктивная критика также приветствуется, чукча понимает, что может ошибаться.
Спасибо, что нашли время прочитать.




















