



Совсем недавно мы опубликовали статью с кратким теоретическим обзором модели данных Звезда. Мы очень рекомендуем почитать ее тем, кто еще не знаком со звездами и снежинками, потому как в этом материале мы постараемся применить всю эту теорию на вполне практической задаче. Для этого мы рассмотрим процесс построения модели для данных из Google Analytics. В качестве поставщика данных будет выступать счетчик нашего блога, как раз сейчас, мы думаем над его модернизацией и узнать больше о статистике посещений нам было бы очень полезно.
Для получения данных из Google Analytics мы воспользуемся нашим сервисом mybi connect, который позволяет выгружать не только фиксированные наборы данных в виде готовых структур, но и произвольные наборы в виде отдельных таблиц. Об этом функционале мы позже опубликуем отдельную инструкцию, а сейчас сосредоточимся на полученных результатах.
upd. выгрузка данных в mybi connect из старого Google Analytics была прекращена, источник был заменен на Google Analytics 4
Основная задача отчета, который мы в итоге хотим получить, является анализ популярности статей, размещенных в блоге. Для этого нас в большей степени интересуют сведения по просмотрам страниц сайта: сколько пользователей и сколько раз их просматривали, сколько времени они на них провели, глубина прокрутки страницы и т.д.
С задачей и источником мы определились, теперь нужно понять как и что мы сможем выгрузить из Google Analytics. Получить данные из этого сервиса веб-аналитики можно только по стандартному API отчетов, который имеет ряд известных ограничений:
- показатели агрегируются на основе параметров, используемых в отчете;
- отчет может содержать ограниченное количество показателей и параметров.
Исходя из этого становится понятно, что мы не сможем сразу выгрузить все необходимые нам сведения. Данные нужно будет выгружать в виде отдельных таблиц, которые в последующем мы должны каким-то образом объединить. Угадайте в какую модель?)
Для того, чтобы получить данные с минимальной гранулярностью, мы воспользуемся разметкой посетителей сайта и их сеансов при помощи пользовательских параметров, в которых будут сохраняться уникальные идентификаторы. Это вызвано тем, что Google Analytics не возвращает необходимые нам идентификаторы через API, и поэтому придется делать это самим. Более подробно о дополнительной настройке Google Analytics можно прочитать здесь.
Передача необходимых идентификаторов в нашем блоге уже была настроена некоторое время назад, поэтому далее мы сразу переходим к выгрузке отчетов с нужными параметрами.
В первую очередь нам необходимо создать отчет по сеансам, который будет содержать базовые параметры и показатели:
- ga:dimension1 – идентификатор пользователя;
- ga:dimension2 – идентификатор сеанса;
- ga:date – дата;
- ga:sessions – количество сеансов;
- ga:bounces – количество отказов;
- ga:sessionDuration – длительность.
Загрузив эти данные в Power BI, мы получаем нашу первую таблицу:
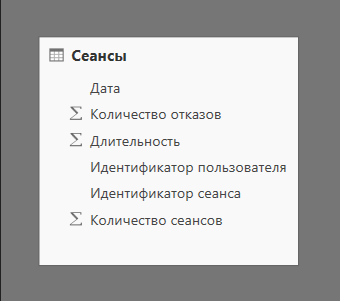
Если рассматривать ее в контексте терминов предыдущей статьи, то она является таблицей фактов, которая содержит идентификаторы необходимые для связи с другими таблицами:
- Идентификатор пользователя;
- Идентификатор сеанса;
- Дата;
и показатели:
- Количество сеансов;
- Количество отказов;
- Длительность.
Продолжаем выгружать таблицы и расширять модель. Далее нам необходимо получить сведения по страницам, которые были просмотрены пользователями при посещении сайта. Для этого мы выгружает отчет следующего вида:
- ga:dimension2 – идентификатор сеанса;
- ga:pagePath – страница;
- ga:pageTitle – название страницы;
- ga:pageviews – количество просмотров;
- ga:timeOnPage – длительность;
- ga:entrances – количество входов;
- ga:exits – количество выходов.
При загрузке этих данных в Power BI нам необходимо сделать несколько преобразований:
- Вынести сведения по страницам в отдельную таблицу;
- Добавить уникальный идентификатор просмотра (его мы используем позже, пока не обращайте на него внимания;).
Благодаря этому мы сможем получить модель имеющую следующий вид:

Думаю, на этом моменте нужно остановиться и подробнее рассмотреть, что у нас получилось.
Про таблицу «Сеансы» мы уже говорили ранее, это таблица фактов, которая содержит основные показатели сеансов пользователей. Таблица «Просмотры страниц» так же является таблицей фактов, но она содержит сведения по просмотрам страниц в каждом из сеансов.
Здесь у нас появляется новая характеристика, которой обладают все таблицы фактов – это уровень детализации. Он обозначает то событие, сведения о котором содержатся в таблице фактов и детальней которого получить сведения при помощи этой таблицы уже невозможно. В нашем случае это сеанс и просмотр страницы. Таблица «Просмотры страниц» имеет более высокий уровень детализации чем таблица «Сеансы» и содержит специфические показатели, которые относятся именно к просмотрам и которые не могут содержаться в таблицах фактов с более низким уровнем детализации.
Кроме этого мы применили еще один интересный подход, который не используется непосредственно при проектировании баз данных, от куда и берет свое начало схема звезды, но который мы можем использовать при создании моделей в Power BI – это связь двух таблиц фактов. В нашем случае мы сделали связь один ко многим с двунаправленной фильтрацией по полю «Идентификатор сеанса»:
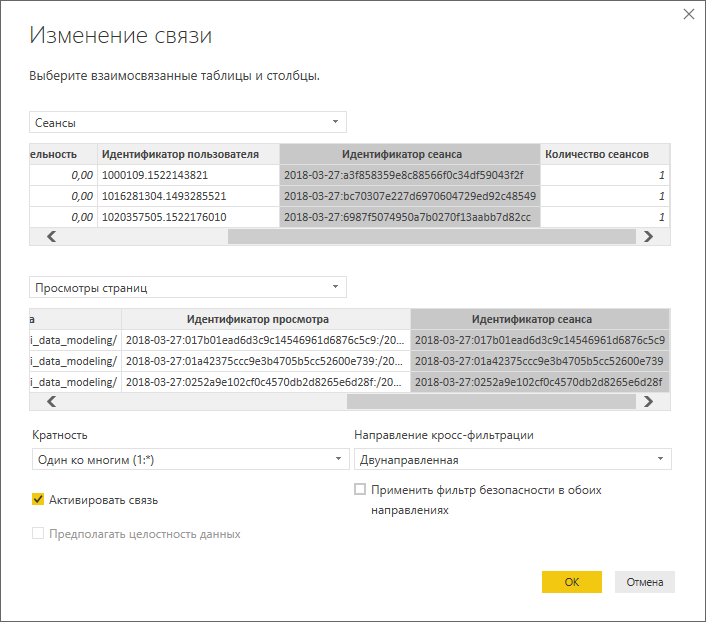
Это возможно потому, что в таблице «Сеансы» для каждого сеанса содержится одна единственная запись, благодаря чему мы можем создать связь с таблицей «Просмотры страниц», в которой для каждого сеанса может содержаться неограниченное количество записей (просмотров страниц).
Следует еще отметить и тот факт, что мы создали дополнительное поле содержащее уникальный идентификатор просмотра, то, про которое забывали;) Идентификатор просмотра представляет из себя объединение идентификатора сеанса и страницы. Он пригодится нам в дальнейшем для подсчета количества уникальных просмотров страниц и для связи с событиями.
Сведения по страницам мы вынесли в отдельную таблицу измерений, что в нашем случае, сделано больше для демонстрации, и связали с таблицей «Просмотры страниц» по полю «Страница», которое мы можем использовать в качестве уникального идентификатора:
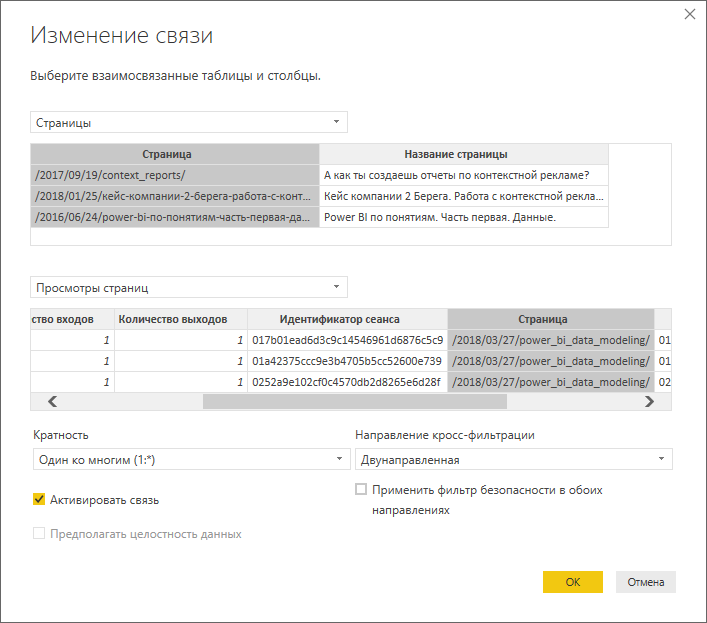
Остальные сведения, которые нас интересуют, передаются в виде событий, поэтому создаем отчет по ним:
- ga:dimension2 – идентификатор сеанса;
- ga:pagePath – страница;
- ga:eventCategory – категория событий;
- ga:eventAction – действие по событию;
- ga:eventLabel – ярлык события;
- ga:eventValue – ценность события;
- ga:totalEvents – всего событий;
- ga:uniqueEvents – уникальные события.
Если рассматривать эти данные как очередную таблицу фактов, то она имеет еще более высокий уровень детализации, так как на одной странице может произойти несколько событий. Поэтому мы в ней создаем новое поле с идентификатором просмотра по которому делаем связь между таблицами «Просмотры страниц» и «События»:

В результате мы получаем модель, имеющую следующий вид:

Таблица «События» в нашем случае выступает в качестве вспомогательной и необходима нам лишь для расчета дополнительных мер, так что мы оставим в таком виде и не будем выносить параметры событий в отдельную таблицу измерений, как диктует теория. В данном конкретном случае это не будет иметь никакого значения.
В результате всех манипуляций мы получили ядро нашей модели, состоящее из трех таблиц фактов, которые мы выгрузили из Google Analytics.
Далее мы добавим в модель сведения по источникам трафика, устройствам и местоположениям пользователей. Все эти данные являются обычными таблицами измерений, так как содержат только параметры, и характеризуют непосредственно сеанс, так что в выгрузку отчетов мы добавим идентификатор сеанса, что позволит в последующем связать эти данные с таблицей фактов «Сеансы». Таблицы, которые мы будем выгружать будут иметь следующий вид.
По источникам трафика мы выгружаем следующий набор параметров:
- ga:dimension2 – идентификатор сеанса;
- ga:channelGrouping – группа каналов по умолчанию;
- ga:source – источник;
- ga:medium – канал;
- ga:campaign – кампания;
- ga:adContent – содержание объявления;
- ga:keyword – ключевое слово;
- ga:sessions – количество сеансов.
По устройствам мы выгрузим следующие данные:
- ga:dimension2 – идентификатор сеанса;
- ga:browser – браузер;
- ga:browserVersion – версия браузера;
- ga:operatingSystem – операционная система;
- ga:operatingSystemVersion – версия операционной системы;
- ga:deviceCategory – тип устройства;
- ga:sessions – количество сеансов.
И наконец местоположения посетителей:
- ga:dimension2 – идентификатор сеанса;
- ga:country – страна;
- ga:region – регион;
- ga:city – город;
- ga:longitude – долгота;
- ga:latitude – широта;
- ga:sessions – количество сеансов.
Вы, наверно, заметили, что в каждом выгружаемом отчете содержатся не только параметры, но и показатель «Количество сеансов». Следует отметить, что мы его использовать не будем, он необходим просто для формирования отчетов в Google Analytics, так как наличие показателя в отчете является обязательным.
После того как мы добавили три новые таблицы измерений в модель, она у нас приобрела следующий вид, который уже больше похож на тот, который мы рассматривали в качестве примера в предыдущей теоретической статье:
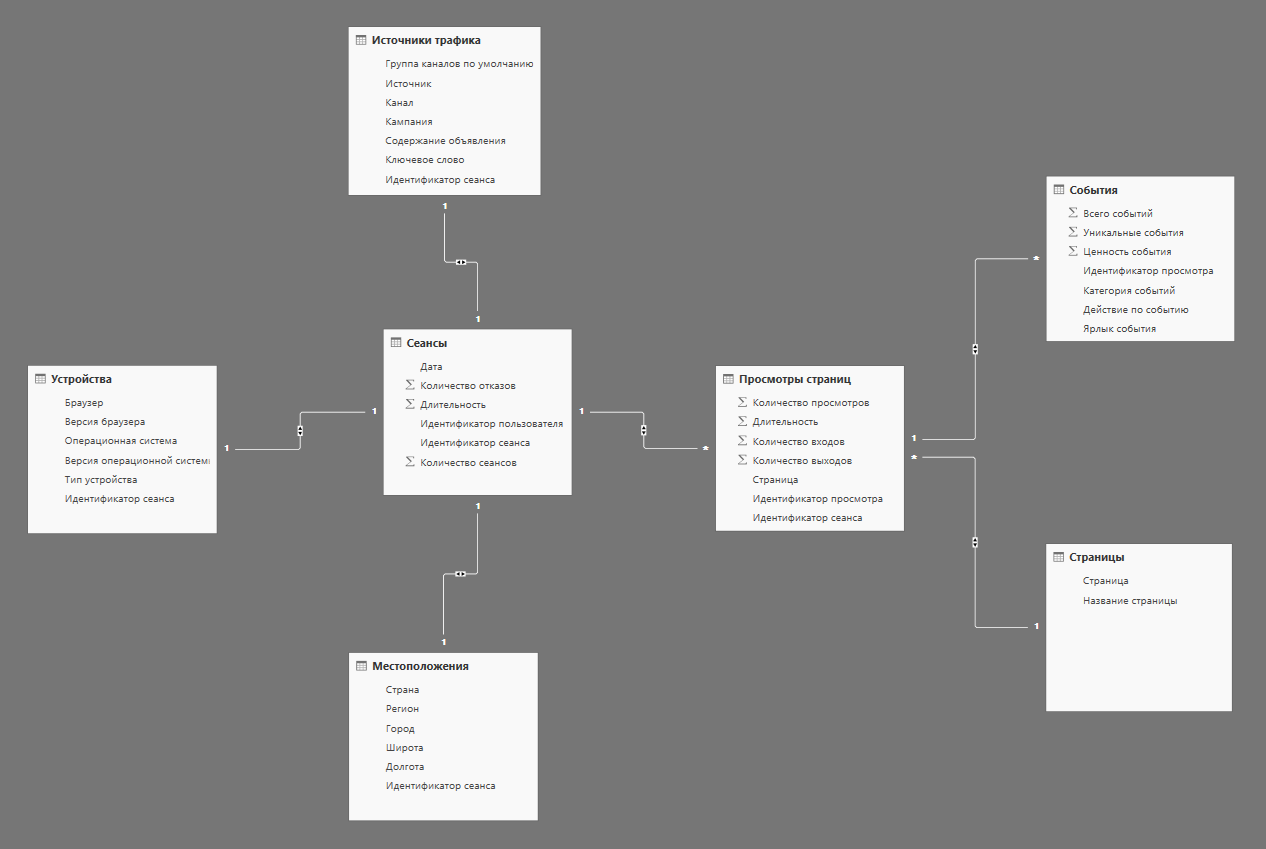
На данный момент мы уже имеем базовую модель, которую можно использовать для создания отчета, но это еще не повод останавливаться. Нам потребуются еще несколько изменений, которые позволят упростить работу с ней.
В первую очередь мы добавим таблицу дат, которую создадим непосредственно в Power BI при помощи DAX:
Параметры дат = ADDCOLUMNS ( CALENDAR ( DATE ( YEAR ( MIN ( 'Сеансы'[Дата] ) ); 1; 1 ); DATE ( YEAR ( TODAY () ); 12; 31 ) ); "Год"; YEAR ( [Date] ); "Квартал"; ROUNDUP ( MONTH ( [Date] ) / 3; 0 ); "Номер месяца"; MONTH ( [Date] ); "Месяц"; FORMAT ( [Date]; "MMMM" ); "Номер недели"; WEEKNUM ( [Date]; 2 ); "Номер дня недели"; WEEKDAY ( [Date]; 2 ); "День недели"; FORMAT ( [Date]; "DDDD" ); "День месяца"; DAY ( [Date] ) )
Причин, чтобы вынести одну единственную дату в отдельную таблицу измерений две и обе, конечно, очень важные:
- В созданной нами таблице дат будет содержаться полный набор дат начиная с начала года минимальной даты из таблицы сеансов и заканчиваю окончанием текущего года. Это необходимо для корректного использования time intelligence функций в DAX
- Использование отдельной таблицы дат позволит формировать срезы одновременно по нескольким таблицам фактам, даже загруженным из различных источников, допустим из Google Analytics и Яндекс.Директ.
Дополнительно мы вынесем часть событий, касающихся просмотров видео, размещенных на страницах сайта, в отдельную таблицу фактов. Это необходимо для того чтобы ее можно было связать с дополнительными справочниками, загруженными из Google Sheets (тоже через mybi connect):
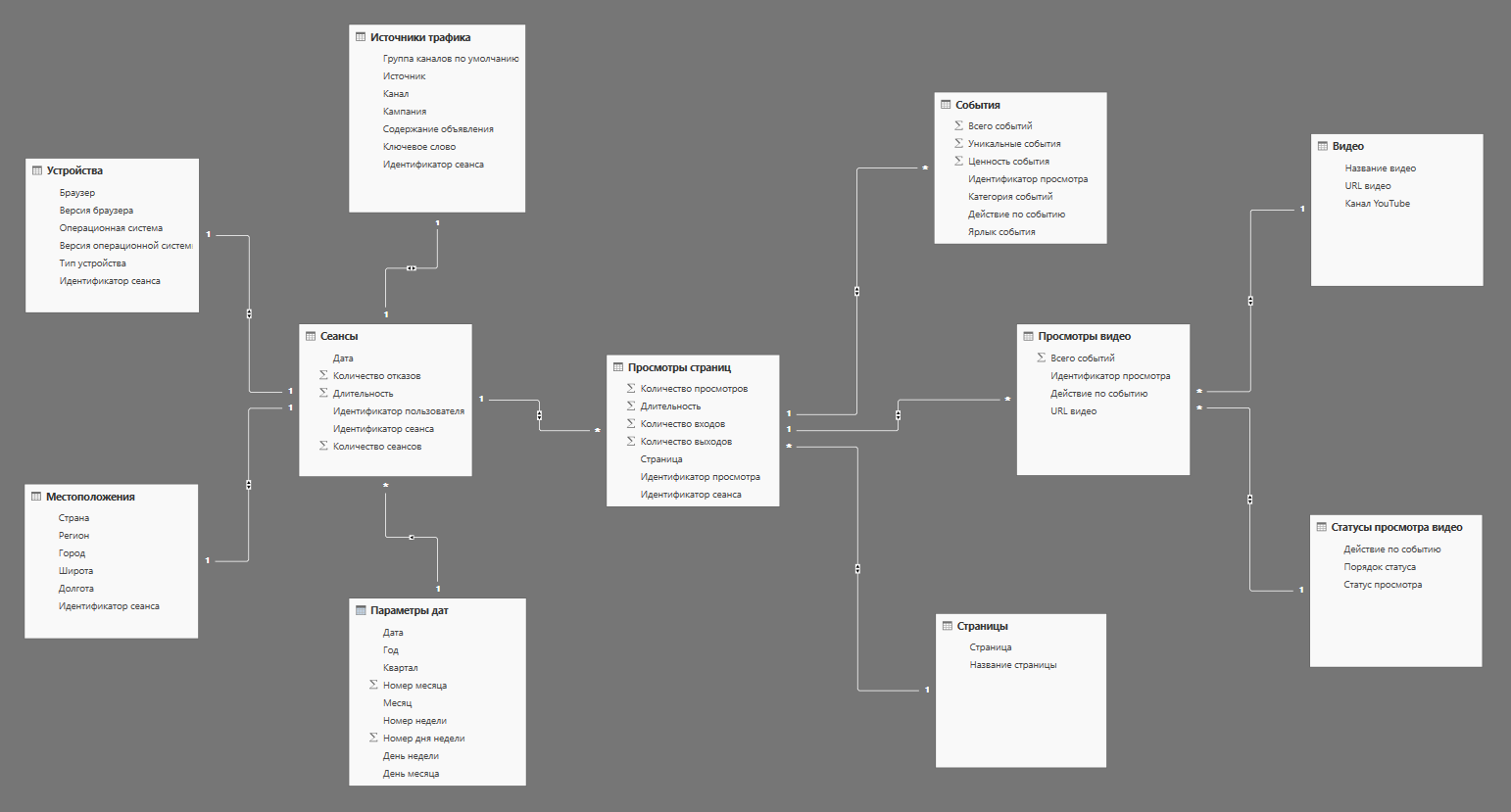
В результате мы получили модель, собранную на классической звезде с несколькими таблицами фактов. В данной модели у нас имеется четыре таблицы фактов:
- Сеансы;
- Просмотры страниц;
- События;
- Просмотры видео;
и семь таблиц измерений:
- Устройства;
- Местоположения;
- Источники трафика;
- Параметры дат;
- Страницы;
- Видео;
- Статусы просмотра видео.
При дальнейшем создании отчета на основе этой модели необходимо руководствоваться правилом, которое мы озвучивали ранее: меры рассчитываются на основе таблиц фактов, а срезы формируются на основе таблиц измерений.
Мы рассмотрели пример того как можно собраться и организовать модель данных в Power BI вручную. Это хорошо в учебных целях, но плохо применимо в реальных условиях, когда требуется легкая тиражируемость. Для этой цели можно воспользоваться базовой выгрузкой данных в нашем сервисе, в результате которой будет выгружена большая часть данных в виде удобном для дальнейшей работы.
Учитывая, что у нас не стояло задачи описать весь процесс создания модели, а мы хотели продемонстрировать то как нужно формировать ее структуру на практике, мы в процессе статьи опустили некоторые моменты, в результате чего было решено предоставить готовую модель для общего доступа, ее можно скачать здесь.
Если же у вас будут какие-то вопросы или комментарии по данной статье, то можете писать их ниже, и мы обязательно на их ответим.
Через некоторое время мы выложим продолжение приключений нашей модели;)











")









