



 Приветствую, коллеги! Меня зовут Дмитрий Веремеев, я являюсь выпускником СПБГТИ(ТУ) 2021 года и занимаю должность бизнес-аналитика в IT-компании из Петербурга. Эта публикация посвящена моему опыту участия в масштабном проекте – Конкурсе ВКР по BI.
Приветствую, коллеги! Меня зовут Дмитрий Веремеев, я являюсь выпускником СПБГТИ(ТУ) 2021 года и занимаю должность бизнес-аналитика в IT-компании из Петербурга. Эта публикация посвящена моему опыту участия в масштабном проекте – Конкурсе ВКР по BI.
Предыстория
Как мне подсказывает опыт, Business Intelligence, практики Big Data, CV, AI и ML на отечественных предприятиях пользуется всё ещё малым спросом, несмотря на то, что именуют себя идущими в ногу с технологиями. Этот примитивный, но тем не менее важный факт натолкнул меня на идею того, “а почему бы не попробовать внести вклад в этот тугоплавкий процесс, написав дипломную работу с применением одной из набирающих популярность технологиях?”. С этого и получила старт история о самом сложным проекте в моей жизни.
Погружение в контекст и предметную область
Предметом исследования выступил кейс внедрения BI-приложения для анализа и управления эффективностью на предприятии тяжёлой промышленности – АО «Средне-Невский судостроительный завод», производящее продукцию как гражданского, так и военного назначения.
Развитие отечественного судостроительного рынка на сегодняшний день неравномерно, и темпы роста количества выпускаемых продуктов нестабильны. В сравнении с зарубежными заводами, трудоемкость производства отечественных в 4-5 раз выше, что приводит к повышению себестоимости постройки судов не менее чем на 70%.
На момент реализации проекта предприятие испытывало ряд проблем, связанных с аналитикой данных и их представлением: для анализа финансовой отчётности организация прибегала к привлечению консалтинговых компаний и не имела технологической базы для аккумулирования широкого массива данных. Используемые аналитические модули к корпоративной ERP-системе требуют непрерывной поддержки, что порождает собой дополнительные издержки, неудобно.
Проблемы необходимо решать и для создания системы аналитической отчётности потребовалось выполнить следующие задачи:
- в первую очередь, исследовать технологию BI для анализа эффективности деятельности организаций;
- сформировать требования к разрабатываемому решению;
- спроектировать концепцию работы решения;
- сформировать перечень инструментов для достижения цели;
- разработать модель по проектируемой концепции;
- реализовать разработанную модель в реальных условиях;
- разумеется, оценить экономическую эффективность разработанного решения.
Архитектура решения
Длительный ресёрч и выявление best practice’ов как отечественных, так и зарубежных коллег позволили мне сформировать универсальную архитектуру будущего решения, которая покрывает ключевые моменты из бэклога проекта.
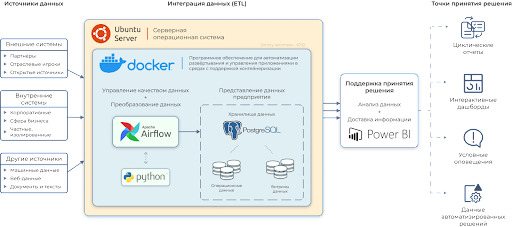
Как видно из модели, имеется четыре распределённые зоны, реализация каждой из которых непосредственно влияет на результат. Однако в ходе разработки от части компонентов пришлось отказаться в угоду удобства конфигурирования и сжатым срокам. В конечном варианте перечень следующий:
- Источники данных: ERP-система, ITSM-система (БД – MySQL), Excel-отчётность;
- Интеграция данных: ETL-инструмент Apache Airflow;
- Представление данных: PostgreSQL;
- Визуализация и поддержка принятия решения: Microsoft Power BI Desktop;
Таким образом, реализации с нуля подверглись компоненты, которые фактически являются неким middleware между данными, генерируемыми ежеминутно и BI-отчётами, которые обновляются согласно расписанию.
Реализация “боевого” решения
В ходе разработки не обошлось без ряда проблем.
В первую очередь, ключевые приложения (ETL-инструмент и промежуточное хранилище PostgreSQL) были завёрнуты в контейнеры, что создавало барьеры при наладке взаимодействия систем и отладке потоков данных из точки А, – источников, в точку B – дашборды PBI. Конструкции, которые контролируются Docker’ом, неочевидны и самое “больное” место – это, естественно, образуемые контейнером подсети. Совладать с ними удалось в момент, когда мне под руку попалась команда “docker inspect [container ID]”, которая забрала бубен из моих рук и позволила общаться с контейнерами на их естественном языке.
Как правило, Docker служит изоляционной оболочкой, и хранить в его контейнерах базы данных – безумие. Здесь меня поджидала следующая проблема – корректное монтирование локального серверного хранилища (иными словами, требовалось заставить контейнер смотреть на HDD сервера).
Всё дальше погружаясь в функционал Apache Airflow, в определённый момент я понял, что информация имеет свойство заканчиваться и дальше копать уже некуда. Ру-комьюнити инструмента невелико, а выполнять задачи всё-таки необходимо. Благо, под капотом Airflow всеми знакомый Python, поэтому несколько библиотек и рабочих дней позволили сформировать жизнеспособные ориентированные ациклические графы (в народе DAG’и), которые и выполняли главные функции всего аналитического решения.
Таким образом, удалось достичь верного алгоритма:
- сотрудники предприятия работают, генерируют данные, заполняют отчёты и помещают их в сетевые папки с общим доступом;
- имея стабильное соединение с внутренними системами, Airflow по расписанию обрабатывает и выгружает данные в PostgreSQL (отчёты забираются bash-скриптами и отдаются контейнеру с Airflow);
- данные аккумулируются в промежуточном хранилище PostgreSQL;
- используя родной коннектор к PostgreSQL, данные загружаются в Power BI;
- по размещённым на дашборде визуализациям строятся интерактивные отчёты.
Отчёт в Power BI
Дашборд, представленный ниже, позволил собрать воедино сотни тысяч строк данных из различных отделов предприятия и закрыть проблему с несвоевременностью процесса аналитики.
P.S. данные, представленные в отчёте, являются демо-версией и не отражают действительности.
Ключевые фичи отчёта:
- мониторинг самых важных финансовых показателей в отслеживаемом периоде;
- изменение аналитического контекста за счёт интерактивности;
- текстовые пояснения, зависящие от показателей (не нужно гадать, что значит значение рентабельности капитала в 0,09);
- всплывающие при наведении подсказки на странице анализа ликвидности позволяют эффективно оценивать показатели;
- ускорение принятия решений в области IT-инфраструктуры (например, локации предприятия с наибольшим количеством инцидентов требуют к себе большего внимания, что в будущем обеспечит более стабильную работу IT в данной локации);
- отслеживание выполнения HR-стратегии предприятия;
- отслеживание активности пользователей и их трудовой дисциплины;
- глоссарий отчёта облегчит адаптацию новым пользователям;
- интерфейс отчёта для мобильной версии.
Итоги
Проведение мною мероприятий по реализации ETL-процессов и промежуточного хранилища предоставляет единую точку сбора для получения аналитических данных сразу из нескольких подразделений предприятия, что подразумевает глубокий исторический контекст для бизнеса, обеспечивает агрегирование данных и позволяет сохранить производительность систем-источников.
В результате дашборд и текстовое пояснение разработки были отправлены на конкурс, где, по результатам, я занял 1-е место и победу в номинации “Лучший дашборд Microsoft Power BI”.
Хотелось бы отдельно поблагодарить организаторов конкурса, членов жюри и всех информационных (и не только) партнёров за полученный опыт, оно того действительно стоило!





















