



Мы уверены, что многие читатели нашего блога хорошо разбираются в вычислениях, которые мы приводим в демонстрационных отчетах. Однако новые пользователи Power BI зачастую не знают, что такое DAX и как его можно использовать для расчета необходимых показателей. Поэтому этой статьей мы хотим начать экскурс в основы языка DAX, и в качестве примера мы возьмем отчет по посещаемости блога, который был предоставлен нам командой Mello и который мы уже рассматривали ранее.
Итак, сначала, как полагается, немного теории.
Data Analysis Expressions, сокращенно DAX (и не спрашивайте почему именно так)) – это язык запросов для Power Pivot, Power BI Desktop и SQL Server Analysis Services (SSAS). Это некий набор функций, операторов и констант, которые можно использовать в формуле или выражении, чтобы подсчитывать и возвращать одно или несколько значений. Говоря проще, DAX помогает создавать новую информацию из данных, уже имеющихся в модели.
Этот язык запросов (а это именно язык) включает библиотеку из более чем 200 функций, операторов и конструкций, что обеспечивает огромную гибкость для выполнения различных вычислений.
Идем дальше и разберем, что же такое мера и вычисляемый столбец и чем они все таки отличаются друг от друга.
Мера является базовым понятием в DAX и представляет собой выражение, которое позволяет рассчитать необходимый показатель на основании данных из модели. Пример использования мер, это расчет среднего, суммы, количества уникальных записей и пр.
Вычисляемый столбец не менее важен и также позволяет рассчитать показатели, но подсчет производится для каждой строки таблицы отдельно и результат сохраняется в отдельное поле (новый столбец таблицы). После создания подобного вычисляемого столбца его можно использовать наравне с остальными столбцами модели. Пример использования вычисляемого столбца – создание некоего столбца с ключами (уникальными идентификаторами записей, для связей с другими таблицами).
Продолжим разбираться в основных отличиях между мерами и вычисляемыми столбцами и посмотрим на них с точки зрения ресурсоемкости будущего отчета.
Меры, в отличие от столбцов, вычисляются только во время использования визуализации, в то время как значения нового столбца вычисляются моментально после его создания. Также вычисляемый столбец сохраняется вместе со всей моделью и его значения рассчитываются во время загрузки данных в модель, в то время как для меры хранится только формула, по которой она вычисляется.
И главное, что необходимо всегда помнить – это то, что вычисляемые столбцы используются для формирования значений в контексте каждой отдельной строки, а меры агрегируют эти значения для всей таблицы.
Здесь и далее примем следующие обозначения:
- 'Таблица'
- 'Таблица'[Столбец]
- [Мера]
Теперь можно смело переходить к практике. Разберем как задать меру и вычисляемый столбец, какие они бывают и что умеют делать.
Начнем анализ с разбора одной из простейших мер. Для удобства чтения будем обозначать меры через знак :=, в то время как для столбцов будем использовать стандартный знак равенства.
Ранее мы уже писали о том, что все показатели, существующие в таблицах, мы рекомендуем “оборачивать” мерами, что имеет ряд преимуществ. Подобным подходом мы воспользовались и при сборе модели, которая лежит в основе рассматриваемого в статье отчета. В результате чего в ней довольно много мер, выполняющих простые вычисления, с одной из которых мы и начнем наше знакомство с DAX:
Просмотры страниц := SUM ( 'Просмотры страниц'[Количество просмотров] )
Давайте рассмотрим из чего состоит приведенное выше выражение. С левой стороны от знака равенства указывается название меры, в данном случае это [Просмотры страниц]. Напомним, что названия необходимо давать максимально понятные, чтобы они передавали суть того значения, которое получится в результате вычисления. Это значительно облегчит дальнейшую работу с отчетом и сэкономит массу времени на выяснения что же та или иная мера считает.
Но и увлекаться не стоит: сильно длинные названия давать не советуем, так как с ними потом будет не очень удобно работать. Если же это какая-то специфическая мера и необходимо пояснить что она вычисляет, то лучше добавить описание. Для этого кликаем правой кнопкой мыши на нужной нам мере в списке полей и выбираем пункт:
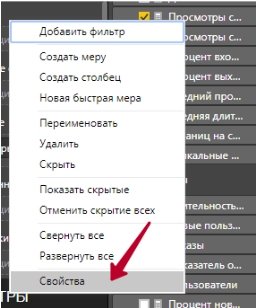
В открывшемся окне Свойство полей в поле Описание смело пишем все, что будущим пользователям отчета нужно знать о мере:
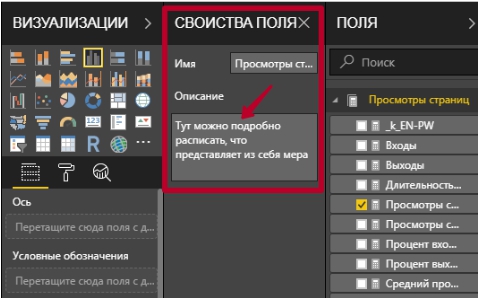
Если после этих манипуляций в списке Полей просто навести мышкой на нужную меру, мы увидим уже не только ее полное название, а и заданное нами описание:
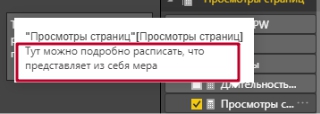
С правой стороны знака равенства мы видим функцию SUM, которая предназначена для суммирования всех значений в столбце, который в свою очередь передается в качестве параметра и в данном случае это 'Просмотры страниц'[Количество просмотров]. Следует отметить, что столбец [Количество просмотров] в данном случае необходимо указывать вместе с названием таблицы 'Просмотры страниц', в которой он находится.
Аналогичным образом, оборачивая столбцы с числовыми значениями, мы получаем и другие меры: [Входы], [Выходы], [Длительность просмотра страницы], [Длительность сеанса] и пр.
Но у нас в отчете есть и другие меры, будем их рассматривать по степени возрастания сложности их синтаксиса. Итак, есть меры, которые представляют собой относительные величины – долю чего либо.
Например:
Процент входов := DIVIDE ( [Входы]; [Просмотры страниц]; 0 )
Слева от знака равенства снова название меры (мы больше к этому не будем возвращаться), а справа функция с тремя аргументами:
DIVIDE ( Числитель; Знаменатель; Альтернативный результат )
Все просто: чтоб получить процент входов из числа просмотров, мы делим [Входы] на [Просмотры страницы], и возвращаем ноль, в случае если результат такого деления возвращает ошибку.
Стоит отметить, что [Входы] и [Просмотры страниц], это меры, в которые мы выше оборачивали данные модели.
Аналогичный синтаксис имеют такие меры отчета как [Процент выходов], [Средняя длительность просмотра страницы], [Страниц на сеанс] и пр. Все их можно найти в разделе Поля в так называемых таблицах мер, у нас в отчете их две 'Просмотры страницы' и 'Сеансы'.
Рассмотрим еще одну не сложную, но полезную функцию, используемую в расчете меры:
Пользователи := DISTINCTCOUNT ( 'Сеансы'[Идентификатор пользователя] )
Эта мера возвращает только уникальные записи из таблицы 'Сеансы', а именно из столбца [Идентификатор пользователя]. Почему именно так? Потому что, один пользователь может просматривать несколько страниц и при том не один раз. В таблице в этом случае будет несколько идентификаторов пользователя (т.е. сколько просмотров – столько и идентификаторов). А нам важно узнать сколько уникальных пользователей просмотрело страницу. Поэтому мы считаем сколько уникальных идентификаторов (уникальных пользователей) есть в нашей таблице с данными.
Теперь перейдем к более сложным расчетам и рассмотрим такую меру:
Средний процент прокрутки страницы := AVERAGEX ( CALCULATETABLE ( GROUPBY ( 'События'; 'События'[Идентификатор просмотра]; "Процент прокрутки"; MAXX ( CURRENTGROUP (); VALUE ( 'События'[Ярлык события] ) ) ); FILTER ( 'События'; 'События'[Категория событий] = "Max Scroll" ) ); [Процент прокрутки] ) / 100
Начнем разбираться максимально подробно.
Средний процент прокрутки страницы – это показатель, который говорит нам о том, на сколько процентов пользователи при посещении страницы прокручивают ее.
Теперь разберемся, как он считается.
У нас есть нужная таблица со всеми необходимыми нам исходными данными, это таблица 'События', где содержится вся информация по всем событиям, произошедшим на странице. Более подробно с содержанием этой таблицы Вы можете ознакомиться в нашей статьей “Пример построения модели на данных Google Analytics”.
Но таблица 'События' содержит также и много ненужной нам сейчас информации. Так например, в таблице собраны вместе все категории событий, в то время как нам нужна только категория Max Scroll. Можно увидеть, выбрав эту категорию, что ярлык события в этом случае будет как раз равен проценту прокрутки страницы для каждого просмотра (Идентификатор просмотра).
Осталось понять, как посчитать среднее
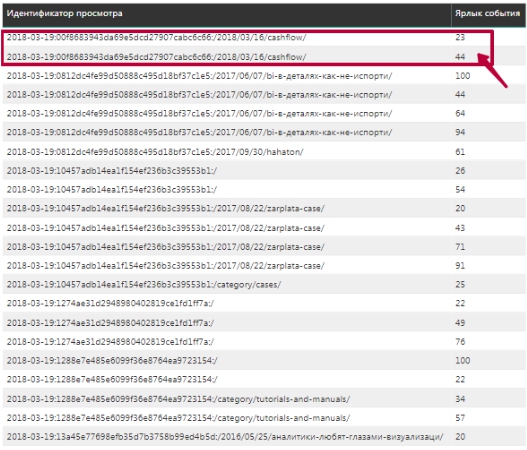
Из таблицы выше видно, что в исходных данных каждому Идентификатору просмотра может соответствовать несколько значений Ярлыка событий. Соответственно сколько событий прокрутки страницы было, столько у нас будет и Ярлыков для заданного просмотра. Все логично.
Для того чтоб вычислить средний процент прокрутки, нам нужно будет построить сводную таблицу по таблице 'События', в которую мы соберем все максимальные значения процента прокрутки по каждому отдельному событию:
GROUPBY ( 'События'; 'События'[Идентификатор просмотра]; "Процент прокрутки"; MAXX ( CURRENTGROUP (); VALUE ( 'События'[Ярлык события] ) ) )
В нашем случае получается что мы из исходной таблицы 'События', берем уникальные значения столбца [Идентификатор просмотра], и в столбец с названием [Процент прокрутки] выводим максимальное значение столбца [Ярлык события] в заданной группе CURRENTGROUP.
Далее нам нужно эти сводные данные вывести с учетом фильтра по категории. Для этого используем функцию CALCULATETABLE, которая выведет табличное выражение GROUPBY c учетом фильтра FILTER, с помощью которой мы сможем вычленить из исходных данных только данные категории Max Scroll.
FILTER ( 'События'; 'События'[Категория событий] = "Max Scroll" )
Результатом функции CALCULATETABLE будет вот такая таблица (справа):
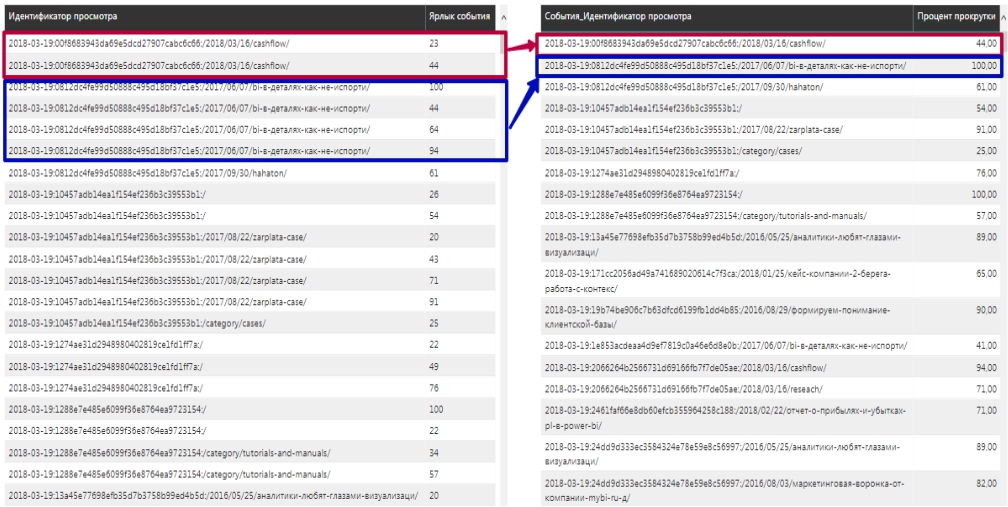
По ней хорошо видно, что расчеты верны, и таблица содержит максимальные значения процента прокрутки для каждого просмотра.
Итак, нам осталось посчитать средний процент прокрутки по полученной сводной таблице, для этого используем функцию AVERAGEX. Остановимся подробнее на этой функции.
Синтаксис у нее такой:
AVERAGEX ( Таблица; Выражение )
где:
- Таблица — исходная таблица или табличное выражение, в которой построчно будет вычисляться выражение из второго аргумента. В нашем случае это наша “виртуальная” таблица с данными максимальных значений прокрутки.
- Выражение — любое выражение, которое в первую очередь выполняется над каждой строкой таблицы из первого аргумента.
В нашем случае вторым аргументом является столбец “виртуальной” таблицы, взятый без изменений и над ним не производится никаких вычислений, но тем не менее мы используем именно итератор AVERAGEX, потому что работаем не со столбцом нашей модели, а с “виртуальной”, специально искусственно созданной нами таблицей, о которой мы рассказывали выше.
Таким образом, функция-итератор AVERAGEX работает поэтапно. Сначала вычисляется выражение из второго аргумента для каждой строки таблицы, указанной в первом аргументе. Затем функция агрегирует эти значения и считает среднее по данным, получившимся по итогам расчета Выражения.
Аналогично работают и другие функции-итераторы, например SUMX – сначала рассчитывает построчно результат Выражения, а затем суммирует эти данные; а MAXX – также сначала выполняет действия над каждой строкой Таблицы из первого аргумента, в соответствии с Выражением из второго, а затем берет максимальное из значений всех строк.
Итак, итератор MAXX позволяет нам посчитать максимальный процент прокрутки по нашей “виртуальной” таблице.
Обратим внимание на то, что полученный результат мы еще делим на 100. Это связано с тем, что проценты в исходной таблице заданы не в процентном выражении (например, 44%), а просто как число – 44. Если в этом случае не делить на 100, то мы получили бы 4400%.
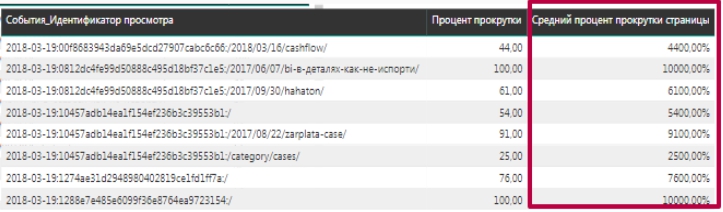
Разделив же на 100, наша меру будет возвращать значение в виде десятичной дроби: 0,44 и для отображения значения в %% останется только на вкладке Моделирование выбрать % формат представления числа:
Готово:

И напоследок рассмотрим еще одну сложную меру, которая, также как и предыдущая, содержит несколько вложенных функций. Надеемся, что на этом этапе вам уже стало немного понятно как и что считают упомянутые меры, поэтому на этот раз мы уже не будем сильно вдаваться в подробности расчетов.
Рассмотрим меру, рассчитывающую кол-во новых пользователей. Выглядит она так:
Новые пользователи := COUNTROWS ( FILTER ( CALCULATETABLE ( ADDCOLUMNS ( VALUES ( 'Сеансы'[Идентификатор пользователя] ); "Дата первого сеанса"; CALCULATE ( MIN ( 'Сеансы'[Дата] ) ) ); ALL ( 'Параметры дат' ) ); CONTAINS ( VALUES ( 'Параметры дат'[Дата] ); 'Параметры дат'[Дата]; [Дата первого сеанса] ) ) )
Рассмотрим синтаксис снаружи-внутрь. Функция COUNTROWS считает кол-во строк в таблице, возвращаемой функцией FILTER, и отфильтрованной по заданным параметрам.
Обратим внимание, что функция фильтрует строки, т.е. столбцы результирующей таблицы остаются неизменны и совпадают со столбцами фильтруемой таблицы, а строки отображаются только те, которые удовлетворяют условию фильтрации.
Как правило эта функция используется не самостоятельно, а внутри DAX выражений, и позволяет создавать промежуточные “виртуальные” таблицы, вместо обычных.
Разберем, что же в итоге получается в результате работы функции FILTER в нашем случае:
FILTER ( Таблица; Фильтр )
Таблицу, которая подвергается фильтрации, возвращает функция:
CALCULATETABLE ( ADDCOLUMNS ( VALUES ( 'Сеансы'[Идентификатор пользователя] ); "Дата первого сеанса"; CALCULATE ( MIN ( 'Сеансы'[Дата] ) ) ); ALL ( 'Параметры дат' ) )
С помощью функции ADDCOLUMNS мы к таблице, состоящей из одного столбца с уникальными идентификаторами пользователей, сформированной выражением VALUES ( 'Сеансы'[Идентификатор пользователя] ), добавляем столбец под названием [Дата первого сеанса], и содержит он следующие значения:
CALCULATE ( MIN ( 'Сеансы'[Дата] ) )
минимальную (первую) дату сеанса, т.е по сути появление нового пользователя.
Затем, с помощью функции CALCULATETABLE, получаем нужную нам для дальнейших расчетов таблицу, при этом мы снимаем фильтр с помощью функции ALL ( 'Параметры дат' ), тем самым охватывая уже весь период времени. Это значит, что в этой функции на таблицу 'Параметры дат' не наложены фильтры.
А условие фильтрации полученной выше таблицы, в свою очередь выглядит так:
CONTAINS ( VALUES ( 'Параметры дат'[Дата] ); 'Параметры дат'[Дата]; [Дата первого сеанса] )
Это означает, что таблицу из первого аргумента функции FILTER мы фильтруем таким образом, чтоб выполнялось условие: набор уникальных дат, который возвращает функция VALUES ( 'Параметры дат'[Дата] ) должен содержать даты, соответствующие дате первого сеанса, созданной выше. Таким образом, отбирая в справочнике дат только даты первого сеанса, мы отберем именно новых пользователей.
Надеемся, что с мерами теперь стало немного понятнее, рассмотрим теперь вычисляемые столбцы, которые также можно создавать и использовать в Power BI. Напомним, что в отличие от мер, значения таких столбцов рассчитываются для каждой строки таблицы отдельно.
В отчете они активно используются для ABC анализа. Так, прежде всего рассчитывается показатель [Накопительный просмотр страниц].
Накопительный просмотр страниц = CALCULATE ( SUM ( 'Просмотры страниц'[Количество просмотров] ); ALL ( 'Страницы' ); 'Страницы'[Просмотров страницы] >= EARLIER ( 'Страницы'[Просмотров страницы] ) )
Далее производится подсчет суммы количества просмотров для всех страниц с помощью накопительного итога. То есть, в этой сумме для каждой страницы учтены только те просмотры, которые были посчитаны ранее.
Поскольку в ABC анализе производится сравнение накопительного процента с граничными значениями, необходимо предыдущий показатель перевести в процент. Для это создаем дополнительный столбец, где каждое значение столбца [Накопительный просмотр страниц] делим на общую сумму просмотра страниц.
Накопительный процент = 'Страницы'[Накопительный просмотр страниц] / SUM ( 'Страницы'[Просмотров страницы] )
В конце нам требуется отнести все страницы в одну из трех групп:
ABC Класс = SWITCH ( TRUE (); 'Страницы'[Накопительный процент] <= 0,7; "A"; 'Страницы'[Накопительный процент] <= 0,9; "B"; "C" )
Выражение основано на одной функции SWITCH, которая по сути является “переключателем” и предназначена для возвращения определенного значения в зависимости условия которое выполнилось.
SWITCH ( Выражение; Значение; Результат )
Первым параметром может выступать любое выражение на DAX, результатом вычисления которого является единственное значение, в нашем случае это TRUE(), которое возвращает логическое значение истина. В качестве же значений, которые используются для выбора возвращаемого результата у нас используются сравнения, результаты выполнения которых сопоставляются с TRUE(). Так, мы каждую строку столбца 'Страницы'[Накопительный процент] проверяем на удовлетворение одному из двух условий <=0,7 и <=0,9, и если накопительный % меньше или равен 0,7 (70%), то для заданной строки будет проставлена категория А, если меньше или равен 0,9 (90%) – то категория В, а если данные в строке не удовлетворяют ни одному из условий, то категория будет С.
На этом закончим наше первое (и при этом довольно масштабное) знакомство с DAX и оставим материал для других статей на эту тему.
К чему же мы пришли? А пришли мы к выводу о том, что DAX является неотъемлемой частью Power BI и правильное понимание мер и вычисляемых столбцов ощутимо помогает строить качественную и быструю отчетность. Мы разобрали отличия между мерами и вычисляемыми столбцами, и рассмотрели практические примеры использования популярных функций, разобрали синтаксис построения формул и ознакомились с нюансами таких мер, как итераторы.
Также, мы затронули такую интересную тему, как АВС анализ. И кто знает, может скоро мы даже посвятим ему отдельную небольшую статью 🙂





















