



Ранее, мы опубликовали статьи, посвященные построению универсальной отчетности в amoCRM (Анализ данных amoCRM с помощью Power BI (часть 1 – Моделирование), Анализ данных amoCRM с помощью Power BI (часть 1 – Визуализация)) и показали, как получить данные при помощи myBI Connect, как устроены связи между сущностями, как можно наглядно представить основные показатели деятельности и, как следствие, увеличить продуктивность работы компании.
Этой статьей мы продолжаем серию публикаций, посвященных этой теме, в ней мы более подробно рассмотрим две меры: конверсия в замер колл-центр, NPS. Но прежде чем приступить к данному этапу, мы рекомендуем вам ознакомиться с прошлым материалом, а также скачать отчет и самостоятельно взглянуть на таблицы, меры и визуализации, чтобы вам легче было понять данный материал.
Конверсия в замер колл-центр
Эта мера представляет собой отношение количества замеров на количество заявок, то есть по данному показателю мы можем судить насколько хорошо менеджер выполняет свою работу (привлекает клиента).
Мера выглядит следующим образом:
Конверсия в замер колл-центр = DIVIDE ( CALCULATE ( [Количество замеров]; USERELATIONSHIP ( 'AMO Дополнительные параметры сделок'[Менеджер 1 воронки]; 'AMO Параметры пользователей'[Имя] ) ); [Количество обращений] )
Первое, что бросается в глаза, это две таблицы: 'AMO Дополнительные параметры сделок', 'AMO Параметры пользователей'. Они помогут нам подсчитать показатель относительно только менеджеров, работающих на 1 воронке (в колл-центре).
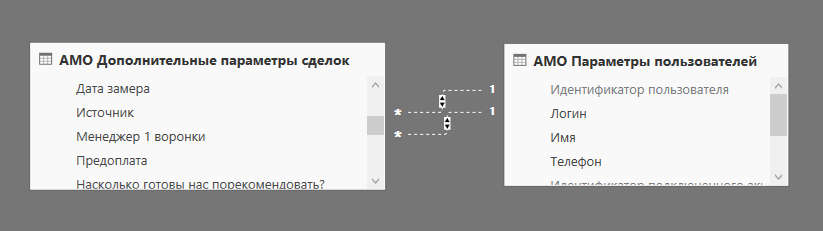
Обратите внимание, что между этими таблицами нет активной связи, но эту проблему мы решаем с помощью специальной функции DAX – USERELATIONSHIP. Синтаксис имеет следующий вид:
USERELATIONSHIP ( 'Таблица1'[Название 1]; 'Таблица2'[Название 2] )
Функция активирует нужную связь во время вычисления выражения (деактивируя прежнюю связь, если такая имеется).
Где:
- 'Таблица1'[Название 1] – столбец первой таблицы, используется как начальная точка связи. В нашем случае это 'AMO Дополнительные параметры сделок'[Менеджер 1 воронки];
- 'Таблица2'[Название 2] – столбец второй таблицы, используется как конечная точка связи. В нашем случае это 'AMO Параметры пользователей'[Имя];
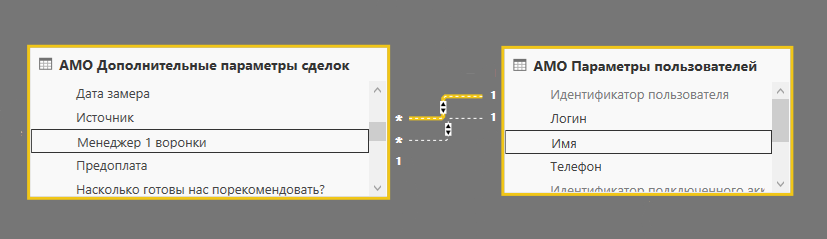
Следует отметить, что USERELATIONSHIP может использоваться только в функциях, которые принимают фильтр в качестве аргумента. В нашем случае такой функцией является CALCULATE. Таким образом, фильтр USERELATIONSHIP, в рамках расчета заставляет Power BI вычислять [Количество замеров] в соответствии с именами, указанными в столбце [Имя] таблицы 'АМО Параметры пользователей'.
Внимание! Связь должна существовать в модели данных и должна быть установлена как неактивная.
Осталось объяснить последнюю функцию:
DIVIDE ( Числитель; Знаменатель; Альтернатива )
Эта функция производит деление числителя на знаменатель и, если произошла ошибка типа «деление на 0», то выводит параметр «Альтернатива». Альтернатива – необязательный параметр, по умолчанию выводится пустое значение BLANK ().
В нашем случае, числитель – это полученное значение из CALCULATE (), а знаменатель – [Количество обращений].
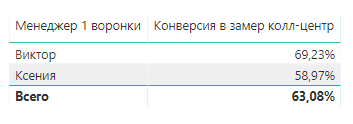
Таким образом, произведя деление количества замеров (количество успешных сделок) на количество обращений (общее количество сделок), мы получим требуемый показатель и сможем оценить качество работы менеджера.
Результат выполнения:
NPS
NPS – это индекс потребительской лояльности. Он показывает готовность клиента совершить повторную покупку или рекомендовать данную компанию другим лицам. Другими словами, это удовлетворенность клиента оказанными услугами.
Этот индекс равен разнице доли промоутеров и критиков. Напомним, что промоутеры это те, кто на вопрос “Насколько готовы нас порекомендовать? Оцените от 1 до 10” оценили нас высоко (9-10 баллов), а критики те, кто дали низкую оценку (6 и меньше из 10).
Мера выглядит следующим образом:
NPS = VAR Answers = CALCULATE ( COUNTA ( 'AMO Дополнительные параметры сделок'[Насколько готовы нас порекомендовать?] ); FILTER ( 'AMO Дополнительные параметры сделок'; 'AMO Дополнительные параметры сделок'[Насколько готовы нас порекомендовать?] <> BLANK () ) ) RETURN ( CALCULATE ( COUNTA ( 'AMO Дополнительные параметры сделок'[Идентификатор сделки] ); FILTER ( 'AMO Дополнительные параметры сделок'; 'AMO Дополнительные параметры сделок'[NPS классификация] = "Промоутеры" ) ) / Answers - CALCULATE ( COUNTA ( 'AMO Дополнительные параметры сделок'[Идентификатор сделки] ); FILTER ( 'AMO Дополнительные параметры сделок'; 'AMO Дополнительные параметры сделок'[NPS классификация] = "Критики" ) ) / Answers )
Данная мера несколько отличается своей конструкцией от других. Давайте разберемся в чем дело.
Здесь мы реализовали новый подход в написании кода – использовали переменную.
Синтаксис:
Мера = VAR a = код 1 VAR b = код 2 RETURN a + b
где a, b – имена переменных. Имя переменной может содержать буквы (a-z, A-Z), цифры (0-9) и символы подчеркивания (_), но оно не может начинаться с цифры. Служебные слова, имена таблиц и пробелы в качестве имени переменной не допускаются.
Переменная – это имя с которым связывается некоторое значение, и которое может передаваться другим функциям в качестве аргумента.
Ключевое слово VAR вводит определение переменной. Их может быть несколько, но каждая должна начинаться с VAR. Ключевое слово RETURN определяет выражение, возвращаемое в качестве результата. Иными словами, после слова RETURN заканчивается определение переменных и начинается основной код формулы.
Отметим ряд важных моментов:
- переменная может быть как значением, так и таблицей;
- переменные могут ссылаться на другие переменные;
- переменные рассчитываются один раз, поэтому в целом сокращается время расчета сложного кода;
- как только переменной присвоено значение, оно не может измениться во время выполнения части RETURN. В данном контексте, переменные могут выступать в роли констант;
- Переменные наглядно упрощают сложный код.
В нашем случае, переменной является Answers.
Значение переменной следует из ее названия и означает ответы пользователей. Мы подсчитываем (функция CALCULATE) количество ответов пользователей (функция COUNTA) при условии (функция FILTER), что ячейки столбца [Насколько готовы нас порекомендовать?] таблицы 'АМО Дополнительные параметры сделок' не пусты.
Далее в основном теле кода (после слова RETURN) мы вычисляем наш показатель, используя созданную нами переменную.
Долю промоутеров мы вычисляем следующим образом:
Подсчитываем количество строк в столбце [Идентификатор сделки], которые имеют значение “Промоутеры” и делим на общее количество ответов (переменную Answers). То есть мы сначала фильтруем таблицу 'АМО Дополнительные параметры сделок'по условию 'AMO Дополнительные параметры сделок'[NPS классификация] = “Промоутеры”,

а затем в получившейся таблице считаем количество строк и выполняем деление.
Долю критиков так:
Подсчитываем количество строк в столбце [Идентификатор сделки], которые имеют значение “Критики” и делим на общее количество ответов (переменную Answers). То есть мы сначала фильтруем таблицу 'АМО Дополнительные параметры сделок' по условию 'AMO Дополнительные параметры сделок'[NPS классификация] = “Критики”,
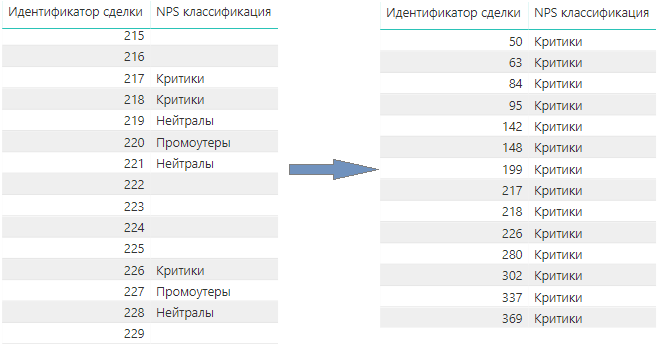
а затем в получившейся таблице считаем количество строк и выполняем деление.
Далее подсчитаем их разницу и получим необходимый нам показатель NPS.
Мы упоминали выше, что переменные помогают улучшить читабельность и восприятие кода, но вам не кажется, что эта мера все равно имеет громоздкий вид? Можно ли как-нибудь ее упростить?
Для начала давайте разберемся с определением Answers.
Мы можем избавиться от функции CALCULATE, использовав только функцию COUNTA, которая сама по себе подсчитывает количество непустых строк в столбце без задания дополнительных фильтров.
Тогда мы получим следующее:
Answers = COUNTA ('AMO Дополнительные параметры сделок'[Насколько готовы нас порекомендовать?] )
Теперь давайте подумаем, как вообще избавиться от конструкции VAR-RETURN?
Мы можем себе это позволить, так как перегруппировка слагаемых (вынесем за скобки общий делитель, который имеет вид: COUNTA ('АМО Дополнительные параметры сделок'[Насколько готовы нас порекомендовать?] )) избавит нас от двойного упоминания переменной Answers, а тогда потеряется смысл в ее использовании. При этом, заменим COUNTA на функцию COUNTROWS, которая считает количество строк в таблице, так как фильтр в CALCULATE нам и так дает непустые строки.
Тогда мы получим следующий вид формулы:
NPS = ( CALCULATE ( COUNTROWS ( 'AMO Дополнительные параметры сделок' ); 'AMO Дополнительные параметры сделок'[NPS классификация] = "Промоутеры" ) - CALCULATE ( COUNTROWS ( 'AMO Дополнительные параметры сделок' ); 'AMO Дополнительные параметры сделок'[NPS классификация] = "Критики" ) ) / COUNTA ('AMO Дополнительные параметры сделок'[Насколько готовы нас порекомендовать?] )
Обратите внимание, что запись
CALCULATE ( COUNTROWS ( 'AMO Дополнительные параметры сделок' ); 'AMO Дополнительные параметры сделок'[NPS классификация] = "Критики" )
эквивалентна
CALCULATE (
COUNTROWS ( 'AMO Дополнительные параметры сделок'[Идентификатор сделки] );
FILTER (
ALL ( 'AMO Дополнительные параметры сделок'[NPS классификация] );
'AMO Дополнительные параметры сделок'[NPS классификация] = "Критики"
)
)
и исходя из стоящей перед нами задачи мы можем использовать первый более сокращенный вид записи в нашей мере.
Таким образом, мы получили более компактную и оптимизированную формулу.
Итак, в этой статье мы рассмотрели две интересные с нашей точки зрения меры: конверсия в замер колл-центр и NPS. Разобрали как можно считать меры через неактивные связи и выяснили как работать с переменными. Но о каких еще мерах и функциях вам бы хотелось узнать подробнее? Свои пожелания вы можете оставить в комментариях, а мы обязательно рассмотрим их в следующих статьях.





















